- 04 July 2025 (2 messages)
-

-

- 05 July 2025 (50 messages)
-

-
-
Two issues which I encountered were:
1) address invalid error: Understand this was due to myself taking a large address range and memory pages were not paged in .
So I reduced the address range to 0x200 and tried using first " u " command on the address which I am trying to monitor.(as mentioned in documentation)
This resolved the issue of invalid address mostly. -
-
-
-
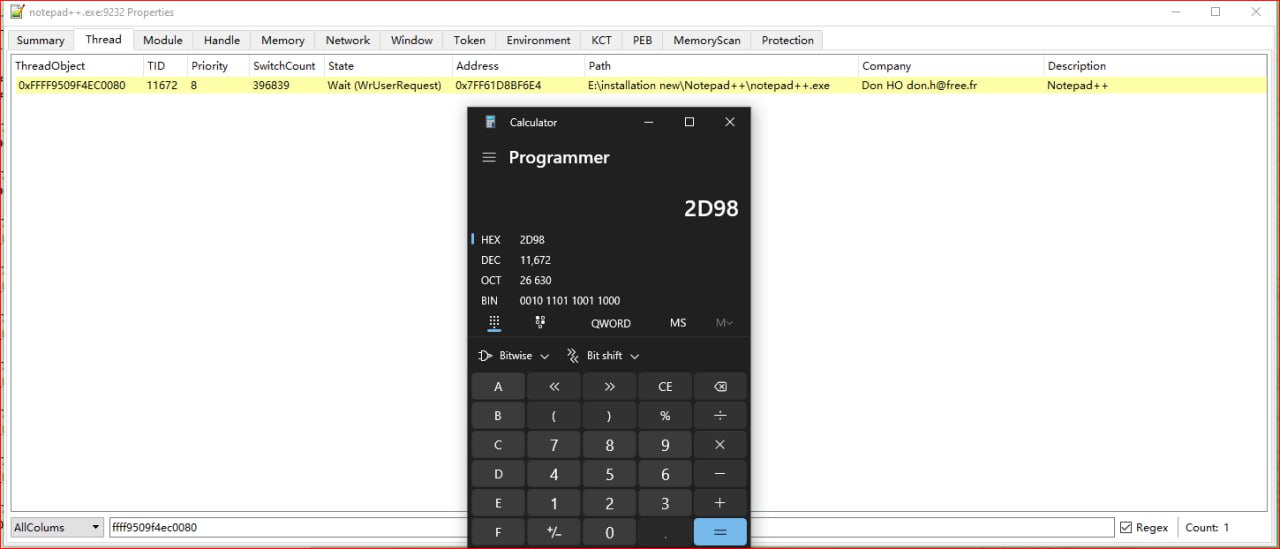
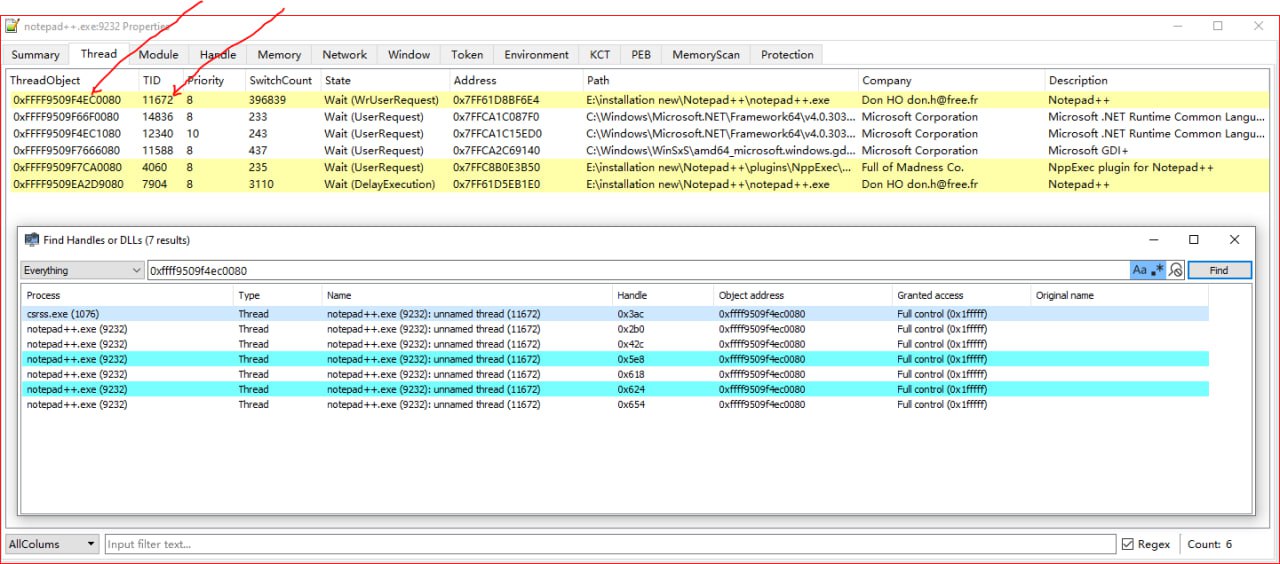
I can find only following output and it used to occur only when i tried to tab-in or bring back notepad++ window:
#################################################################################################
Access_at: 7ff61d4c01b8 FROM addr: 7ffcb2ba29b0, rsp_return _add: c500000001, _p_Ethread: ffff9509f4ec0080, TID: 2d98
Access_at: 7ff61d4c01bc FROM addr: 7ffcb2ba29bf, rsp_return _add: c500000001, _p_Ethread: ffff9509f4ec0080, TID: 2d98
Access_at: 7ff61d4c0000 FROM addr: 7ffcb2ba2b26, rsp_return _add: 0, _p_Ethread: ffff9509f4ec0080, TID: 2d98
Access_at: 7ff61d4c003c FROM addr: 7ffcb2ba2b2c, rsp_return _add: 0, _p_Ethread: ffff9509f4ec0080, TID: 2d98
Access_at: 7ff61d4c0120 FROM addr: 7ffcb2ba2b4b, rsp_return _add: 0, _p_Ethread: ffff9509f4ec0080, TID: 2d98
Access_at: 7ff61d4c0138 FROM addr: 7ffcb2bc7a30, rsp_return _add: 1, _p_Ethread: ffff9509f4ec0080, TID: 2d98
Access_at: 7ff61d4c0138 FROM addr: 7ffcb2bc7a3b, rsp_return _add: 1, _p_Ethread: ffff9509f4ec0080, TID: 2d98
Access_at: 7ff61d4c0170 FROM addr: 7ffcb2bc7a41, rsp_return _add: 1, _p_Ethread: ffff9509f4ec0080, TID: 2d98
Access_at: 7ff61d4c0000 FROM addr: 7ffcb2ba2b26, rsp_return _add: 80000, _p_Ethread: ffff9509f4ec0080, TID: 2d98
Access_at: 7ff61d4c003c FROM addr: 7ffcb2ba2b2c, rsp_return _add: 80000, _p_Ethread: ffff9509f4ec0080, TID: 2d98
//.........................................................
########################################################################################### -
-
-
-
-
-
-
 Hi! How would a process access a different process address? ReadProcessMemory?
Hi! How would a process access a different process address? ReadProcessMemory? -
-
I have a vague memory about ReadProcessMemory working with an APC, let me check
-
In case its APC, it makes sense that you won't see a different thread, because read requests are injected into notepads++ threads
-
-
Hm, I seem to be wrong, MiCopyVirtualMemory actually uses KiStackAttachProcess to swap page tables temporarily
-
I guess it's up to hyperdbg implementation then
-
-
-
 Hey,
Hey,
Generally, it's not supported since it's a bit weird that a process being accessed from another process, though I agree, they might be some cases.
But if you want to do it with HyperDbg, just comment this line of code and recompile HyperDbg, it will show you all accesses from all processes:
https://github.com/HyperDbg/HyperDbg/blob/80a434d49d3af9208004eb00295ed06386a2b3d1/hyperdbg/hyperkd/code/debugger/core/Debugger.c#L1127HyperDbg/hyperdbg/hyperkd/code/debugger/core/Debugger.c at 80a434d49d3af9208004eb00295ed06386a2b3d1 · HyperDbg/HyperDbgState-of-the-art native debugging tools. Contribute to HyperDbg/HyperDbg development by creating an account on GitHub.
-
 [matrix] <Hypercall> Anyone has an idea why my machine hangs?
[matrix] <Hypercall> Anyone has an idea why my machine hangs?
It worked fine before I tried to do syscall hooking via EFER #UD exceptions. But now it hangs right after I virtualize any core.
```c
__vmx_vmwrite(CPU_BASED_VM_EXEC_CONTROL, AdjustControls(CPU_BASED_ACTIVATE_SECONDARY_CONTROLS | CPU_BASED_ACTIVATE_MSR_BITMAP, MSR_IA32_VMX_PROCBASED_CTLS));
__vmx_vmwrite(SECONDARY_VM_EXEC_CONTROL, AdjustControls(CPU_BASED_CTL2_RDTSCP | CPU_BASED_CTL2_ENABLE_INVPCID | CPU_BASED_CTL2_ENABLE_XSAVE_XRSTORS, MSR_IA32_VMX_PROCBASED_CTLS2));
__vmx_vmwrite(PIN_BASED_VM_EXEC_CONTROL, AdjustControls(0, MSR_IA32_VMX_PINBASED_CTLS));
__vmx_vmwrite(VM_ENTRY_CONTROLS, AdjustControls(VM_ENTRY_IA32E_MODE | VM_ENTRY_LOAD_IA32_EFER, MSR_IA32_VMX_TRUE_ENTRY_CTLS));
__vmx_vmwrite(VM_EXIT_CONTROLS, AdjustControls(VM_EXIT_IA32E_MODE | VM_EXIT_SAVE_IA32_EFER | VM_EXIT_ACK_INTR_ON_EXIT, MSR_IA32_VMX_TRUE_EXIT_CTLS));
__vmx_vmwrite(EXCEPTION_BITMAP, 64); // EXCEPTION_VECTOR_UNDEFINED_OPCODE
//__vmx_vmwrite(GUEST_EFER, __readmsr(MSR_IA32_EFER) & ~1); // Invalid guest state. I had to disable it in MsrRead.
__vmx_vmwrite(GUEST_EFER, __readmsr(MSR_IA32_EFER));
// Msr read handler:
if (GuestRegs->rcx == MSR_IA32_EFER) {
Msr.Content = __readmsr(MSR_IA32_EFER);
Msr.Low &= ~1; // Disable syscalls
goto end;
}
if (((GuestRegs->rcx <= 0x00001FFF)) || ((0xC0000000 <= GuestRegs->rcx) && (GuestRegs->rcx <= 0xC0001FFF)))
{
Msr.Content = __readmsr((ULONG)GuestRegs->rcx);
}
end:
GuestRegs->rax = Msr.Low;
GuestRegs->rdx = Msr.High;
``` -
Do not use the EFER technique, it's not stable probably because Microsoft made some intentional modifications to prevent it (just like before). Instead of this, use the !epthook and put the hook into the next instruction after the SWAPGS to hook the syscall, here's an example:
https://docs.hyperdbg.org/commands/extension-commands/syscall#alternative-method-for-syscall-interception!syscall, !syscall2 (hook system-calls) | HyperDbg DocumentationDescription of '!syscall, !syscall2' commands in HyperDbg.
-
Afaik CET reqiures VBS to be enabled to be active
-
VBS is disabled when HyperDbg is running 🤔
-
That's why I don't think CET is the problem
-
Anyway, just a random question — do you know if there are any differences in how a hypervisor should be implemented for hybrid core architectures? I recently noticed that on Meteor Lake bare metal, HyperDbg doesn’t work. I’m still investigating, but I was wondering if the mix of P-cores and E-cores requires any special handling, or if a hypervisor should work without any modifications to support hybrid cores.
-
I couldn't find anything regarding this on Intel SDM. 🤔
-
I indeed had some problems with my MTL NUC. I believe I had a heisenbug which I can't reproduce most of the time. I didn't change anything in the hypervisor, it just started working on its own. It might be a problem with a firmware since I launch as a UEFI app.
Hybrid cores mean that VMCS revisions might be different between P and E cores. This should not be a problem as long as you don't migrate vcpus to different cpu threads.
P and E cores also have a different set of VMX features, but ucode removes those differences by disabling features that are not supported on P and E cores simultaneously. -
I got a shiny new Lunar Lake NUC yesterday and Pulse worked out of the box luckily
-
Oh, okay. It's good to know. We won't migrate VCpus to different core but I also got a MTL NUC today. Gonna test it again and will let you know if I find the problem.
-
Which one did you get?
-
Let me check.
-
ASUS NUC 14 Pro Tall Kit RNUC14RVHU500002I (Intel Core U5 125H Processor)
-
Nice, this one has a decent firmware
-
UEFI firmware?
-
Yep
-
I didn't test it on this NUC yet, but on my system with a System76 (Coreboot as the UEFI firmware), it fails.
-
What fails? Hyperdbg?
-
Yes
-
that's weird because you load your hv in the OS and the firmware doesn't matter at that point
-
Yeah, you're right. It might be for something else (e.g., a crash on HyperDbg codes). I have to see if I could reproduce it on the MTL NUC.
-
Oh, I see. Right, VBS is for kernel CET, my bad
-
Guys.. a question related to virtuealzation
-
In general
-
What would happen 😕 when Microsoft will introduce the new architecture where the antivirus components are isolated in a special place (thanks to crowdstrike incident )
-
I can think that they will force the whole system to be virtuzalized by default and the antivirus space will be controlled by hyper-v or something
-
What would happen in this case to other hypervsiors such hyperdbg ..
- 06 July 2025 (15 messages)
-
Hi Thank you for your reply and help.
-
[matrix] <Hypercall> I really don't want to setup EPT and deal with all of that bullshit. I tried to use MSR_LSTAR hook too but I won't emulate the entire KeSystemCall64. No way. Is there any other way I can hook syscalls? Of course I can hook them in userland but I am worried about direct/indirect syscalls the application might do to evade my hooks.
-
[matrix] <Hypercall> [reply]: They are already doing it... Kinda
-
[matrix] <Hypercall> They are providing methods for intercepting most of the calls. PsSetCreateProcessNotifyRoutine, ObRegisterCallbacks are a few examples
-
[matrix] <Hypercall> And yeah, the EDRs use it
-
[matrix] <Hypercall> That's how it is already. The whole system is virtualized by Windows Defender by default (ref Device Security). However, I did not see an AV/EDR that uses hypervisor (or mentions it does explicitly) to protect the system.
-
[matrix] <Hypercall> [reply]: Should I use the event tracing?
-
[matrix] <Hypercall> I heard Microsoft did some patches to it, but I am not sure.
-
I'm not sure what is their new plan (based on CrowdStrike incident) do you have any link about what modification they'll gonna push into Windows?
-
👍
-
Are you talking about emulating #UDs?
-
If it's the case, I think based on the discussion that we had in the group, it's probably because HyperDbg doesn't handle (emulate) Intel CET stack for the emulation of #UDs to the SYSCALL.
-
From what i have read in twitter , they will remove the antivirus components to a special place and if a antivirus component crushed it will not cause a blue screen , bur how they implement this feature?I don't know but it seems that they will relies on virtualization (like with vbs feature)
-
[discord] <unrustled.jimmies> [reply]: https://blogs.windows.com/windowsexperience/2025/06/26/the-windows-resiliency-initiative-building-resilience-for-a-future-ready-enterprise/
`Next month, we will deliver a private preview of the Windows endpoint security platform to a set of MVI partners. The new Windows capabilities will allow them to start building their solutions to run outside the Windows kernel. `
Looks like they are just going to be offered a set of enlightened APIs to code against so the EDR drivers can run in UM instead of needed to run as an ELAM driver in KM. (Gotta wait and see how this pans out tho)
As long as SecureBoot isn't forced, anything will still be possible ofc. It would just take more work.The Windows Resiliency Initiative: Building resilience for a future-ready enterpriseResilience isn’t optional—it’s a strategic imperative. In today’s threat landscape, organizations can’t afford to treat resilience as a reactive measure. It must be built into the foundation of how systems are designed, secured and managed
-
Joined.
- 07 July 2025 (5 messages)
-

-
This is really interesting. Thanks for sharing.
-
Generally, I don't think it needs any modification on the HyperDbg side from the description of the above blog post, but of course, we cannot be sure about it before it's released, so let's see what the outcome will be.
-
[discord] <unrustled.jimmies> [reply]: Unrelated question. I was just wondering why did you disable using IST when separate IDT from OS is enabled? Does it cause issues or for some other reason? - https://github.com/HyperDbg/HyperDbg/blob/80a434d49d3af9208004eb00295ed06386a2b3d1/hyperdbg/hyperhv/header/memory/Segmentation.h#L41C9-L41C35HyperDbg/hyperdbg/hyperhv/header/memory/Segmentation.h at 80a434d49d3af9208004eb00295ed06386a2b3d1 · HyperDbg/HyperDbg
State-of-the-art native debugging tools. Contribute to HyperDbg/HyperDbg development by creating an account on GitHub.
-
I don't remember exactly why, but I think we disabled it so we could reuse the VMX root-mode stack and save memory.
- 09 July 2025 (4 messages)
-
[discord] <inflearner> [reply]: Sounds pretty illegal
-
[discord] <rayanfam> [reply]: It was a spam. Removed.
-
Joined.
-
An Amazing Discovery for Hypervisor Developers Featuring a Lunar Lake CPU
I recently purchased a NUC—specifically, the ASUS NUC 14 Pro AI, which features a 288V Lunar Lake CPU. I dumped its VMX capabilities to update the VMX capability table at pulsedbg.com/vmx.html
During my analysis, I noticed that the IA32_VMX_PROCBASED_CTLS3 MSR has a reserved bit set—bit 9. This isn’t entirely surprising; the Intel SDM has missed details before. For instance, bit 57 of IA32_VMX_BASIC MSR is also set on ADL+ CPUs. I’ve marked it as an undocumented bit because I can't disclose its purpose and also can't compel anyone to document it in the SDM.
But unlike IA32_VMX_BASIC, which is just an informational MSR, IA32_VMX_PROCBASED_CTLS3 is more significant—it controls modifiable behavior in the VMCS. So, the big question: What does bit 9 actually enable?
After considerable research, I finally found the answer in the Intel® Architecture Instruction Set Extensions Programming Reference. It’s part of a feature called TSE (Total Storage Encryption), which introduces a new instruction: PBNDKB. That undocumented bit enables support for this instruction in guest VMs; otherwise, it triggers a #UD (Undefined Instruction) exception.
Interestingly, TSE was expected to debut with Lunar Lake CPUs. Even more surprising, there’s already a Visual Studio 2022 intrinsic available for the PBNDKB instruction—even though it’s not yet documented in the SDM!
Lesson learned: don’t rely solely on the SDM—be sure to check all Intel technical documentation, including what's available at
https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.htmlManuals for Intel® 64 and IA-32 ArchitecturesThese manuals describe the architecture and programming environment of the Intel® 64 and IA-32 architectures.
- 10 July 2025 (4 messages)
-
[discord] <ohault> [reply]: Is there already an open source project as a replacement of SDM ?
-
I'm not sure I get that. It's the official documentation by Intel. How would anybody else create such documentation?
-
[discord] <ohault> [reply]: I’m referring here a simulator implementation more than documentation
-
Like bochs?
- 13 July 2025 (2 messages)
-
Hi guys, do you know how I can log all critical events ? Like VMEntries , and stuff ?
My Windows just hangs when launching a certain kernel driver ☠️ -
I’m trying to understand why
- 14 July 2025 (1 messages)
-
 Curious about anti-anti-debugging techniques and hiding hypervisors from malware? Slides are up for our ECOOP/DEBT 2025 talk where we present HyperEvade, our upcoming hypervisor transparency extension for @hyperdbg:
Curious about anti-anti-debugging techniques and hiding hypervisors from malware? Slides are up for our ECOOP/DEBT 2025 talk where we present HyperEvade, our upcoming hypervisor transparency extension for @hyperdbg:
https://github.com/HyperDbg/slides/blob/main/2025/DEBT2025/hyperevade-ecoop2025-debt.pdf
HyperEvade is targeted for @hyperdbg 's next major release - so watch this space! - 15 July 2025 (3 messages)
-
 Joined.
Joined. -
Does it support nested virtualization?
-
[discord] <inflearner> With VMWare yes, Hyper-V I had some issues
- 16 July 2025 (8 messages)
-

-
remote debugging but you need 2 pcs
-
[discord] <inflearner> [reply]: I have 2 pcs that not a problem.
I just can't seem to find a function in the documentation to log all events ? VMExits etc.... You have an idea ? -
What do you mean by logging VM-exits?
-
[discord] <inflearner> [reply]: When I launch EAC, i get a system freeze, I would like to understand where it's comming from.
I was thinking of logging all VM-Exits that occur in the HV to understand which one is freezing. -
HyperDbg has different events (syscall, EPT instruction and monitoring hooks, IO hooks, CPUIDs, MSR hooks, etc.), it doesn't show you all VM-exits without relating them into some useful events.
-
[discord] <inflearner> [reply]: Ohh okay I see, thanks, i'll check that out
-
Please do not mention any specific software or anti-cheat software. It's considered illegal in many places. But, in general, you could add a 'LogInfo' into the VM-exit handler of HyperDbg and it logs all of the VM-exits for you, but I doubt that it would be useful since HyperDbg is dealing with a lot of VM-exits most of them are unrelated and system specific (e.g., VM-exits for instructions that cause unconditional VM-exits).
- 18 July 2025 (1 messages)
-
Joined.
- 19 July 2025 (59 messages)
-
[discord] <cowtickle> [reply]: system freeze or a BSOD?
-
[discord] <inflearner> [reply]: System Freeze
-
If you're using Windows 11 24h2 on a raptor lake processor or Meteor Lake (and probably Lunar Lake or older processors), the reason why it freezes the system is because Windows starts executing TPAUSE instruction on these processor and HyperDbg didn't enable it by default on Proc based CTL2. The solution to this is to switch to the latest commit on the 'dev' branch. So, your system won't freeze again, however, I noticed that on these processors after working with the system for a couple of minutes, random EPT Violations happens, which I don't have any idea why. I'm currently investigating these random EPT Violations on bare metal systems.
-
[discord] <cowtickle> [reply]: interesting, I've seen BSODs from similar software before but not them nuking the hypervisor itself
-
[discord] <cowtickle> my guess was that they can kill what they cna control (the guest kernel so basically the system) but not the hypervisor itself
-
[discord] <inflearner> I’ll retry later, but it seems it’s a freeze yeah, but only when I launch EAC
-
[discord] <inflearner> [reply]: Yeah didn’t make any efforts hiding hyperkd.sys also
-
[discord] <unrustled.jimmies> [reply]: By random you mean the EPT Violation address isn't for a MMIO address higher than the 512GB that's mapped and its sporadic? I had to add the following that just used a shared 1GB page for any EPT violations outside the initially mapped region for this issue but it would be interesting to see what you discover as well if its another edge case.
```c
else
{
//
// Handle unmapped EPT entries for addresses outside the initially mapped range
//
SIZE_T PML4Index = ADDRMASK_EPT_PML4_INDEX(GuestPhysicalAddr);
if (PML4Index >= VMM_EPT_ACTIVE_PML4E_COUNT)
{
PVMM_EPT_PAGE_TABLE EptPageTable = VCpu->EptPageTable;
if (EptPageTable->PML4[PML4Index].ReadAccess == 0)
{
EptPageTable->PML4[PML4Index].PageFrameNumber = g_MmioSharedPml3TablePfn;
EptPageTable->PML4[PML4Index].ReadAccess = 1;
EptPageTable->PML4[PML4Index].WriteAccess = 1;
EptPageTable->PML4[PML4Index].ExecuteAccess = 1;
EptInveptSingleContext(VCpu->EptPointer.AsUInt);
}
return TRUE;
}
}
``` -
This is the EPT violation physical address:
0: kd> dx GuestPhysicalAddr
GuestPhysicalAddr : 0x3ffbffac024 [Type: unsigned __int64] -
and the EPT violation qualification:
0: kd> dx ViolationQualification
ViolationQualification [Type: VMX_EXIT_QUALIFICATION_EPT_VIOLATION]
[+0x000 ( 0: 0)] ReadAccess : 0x1 [Type: unsigned __int64]
[+0x000 ( 1: 1)] WriteAccess : 0x0 [Type: unsigned __int64]
[+0x000 ( 2: 2)] ExecuteAccess : 0x0 [Type: unsigned __int64]
[+0x000 ( 3: 3)] EptReadable : 0x0 [Type: unsigned __int64]
[+0x000 ( 4: 4)] EptWriteable : 0x0 [Type: unsigned __int64]
[+0x000 ( 5: 5)] EptExecutable : 0x0 [Type: unsigned __int64]
[+0x000 ( 6: 6)] EptExecutableForUserMode : 0x0 [Type: unsigned __int64]
[+0x000 ( 7: 7)] ValidGuestLinearAddress : 0x1 [Type: unsigned __int64]
[+0x000 ( 8: 8)] CausedByTranslation : 0x1 [Type: unsigned __int64]
[+0x000 ( 9: 9)] UserModeLinearAddress : 0x0 [Type: unsigned __int64]
[+0x000 (10:10)] ReadableWritablePage : 0x1 [Type: unsigned __int64]
[+0x000 (11:11)] ExecuteDisablePage : 0x1 [Type: unsigned __int64]
[+0x000 (12:12)] NmiUnblocking : 0x0 [Type: unsigned __int64]
[+0x000 (13:13)] ShadowStackAccess : 0x0 [Type: unsigned __int64]
[+0x000 (14:14)] SupervisorShadowStack : 0x0 [Type: unsigned __int64]
[+0x000 (15:15)] GuestPagingVerification : 0x0 [Type: unsigned __int64]
[+0x000 (16:16)] AsynchronousToInstruction : 0x0 [Type: unsigned __int64]
[+0x000 (63:17)] Reserved1 : 0x0 [Type: unsigned __int64]
[+0x000] AsUInt : 0xd81 [Type: unsigned __int64] -
It's not within the first 512 GB. Not a surprise that HyperDbg fails. But curious to know, why do they map it over 512 GB? I didn't see anything like this before 🤔🤔
-
MMIO of course
-
Yes, but is it a common thing? or they just decided to do it recently?
-
Physical address space is not limited by the amount of ram or predefined reserved memory regions. It is limited by CPU capability to address a certain number of bits of a physical address space. You can determine that via CPUID and you should cover the whole physical address space with EPT.
-
It's always been like that, you can map MMIO anywhere you want beyond RAM ranges
-
It breaks some of the HyperDbg's checks. Right now, we check for the validity of a physical address like this:
https://github.com/HyperDbg/HyperDbg/blob/80a434d49d3af9208004eb00295ed06386a2b3d1/hyperdbg/hyperhv/code/memory/AddressCheck.c#L120
Where g_CompatibilityCheck.PhysicalAddressWidth comes from CPUID:
https://github.com/HyperDbg/HyperDbg/blob/80a434d49d3af9208004eb00295ed06386a2b3d1/hyperdbg/hyperhv/code/features/CompatibilityChecks.c#L74HyperDbg/hyperdbg/hyperhv/code/memory/AddressCheck.c at 80a434d49d3af9208004eb00295ed06386a2b3d1 · HyperDbg/HyperDbgState-of-the-art native debugging tools. Contribute to HyperDbg/HyperDbg development by creating an account on GitHub.
-
I think this approach won't work for these MMIO addresses anymore. Do you have any better suggestion? Should we check for MTRR ranges instead of this approach? 🤔
-
No, wait. Your CheckAddressPhysical(UINT64 PAddr) is valid
-
The question is, do you cover the whole physical address space with EPT?
-
No, actually if some one want to read or write into MMIO ranges (e.g., to create PCIe TLP Packets) using HyperDbg, we first check whether the address (MMIO Address) is valid or not. The way that we check it is by using the function that I just sent the link.
-
I mean what if the OS uses those addresses because of MMIO?
-
OS? Isn't it the responsibility of UEFI firmware to map MMIO addresses to physical addresses?
-
But the OS has device drivers. The driver maps MMIO, which is mapped to that far far away physical (system) address. OS driver tries to access MMIO -> EPT violation
-
I guess I need to disambiguate the term 'maps' here. Frimware sets up system address space layout for devices given those devices have UEFI drivers or ACPI methods. There you have physical addresses of MMIO regions for the devices.
-
Windows boots later on and recevies resources lists, including system addresses for MMIO ranges for devices.
-
Respective drivers map those system addresses to kernel virtual ones in order to be able to work with the device MMIO region.
-
So whenever some driver needs to communicate with the device, it tries to access a virtual address for that MMIO ranges. MMU translates it to a far-far away physical address. And then it fails, because it's virtualized and EPT has no entry for that guest physical address.
-
This is why you should map the whole guest physical address space in EPT.
-
I know it's rather big, but this is the exact reason why large and huge EPT pages exist.
-
I know, many vendors try to keep system address space compact. But it is not a must, you can place your MMIO regions almost anywhere you want.
-
Well, I think it breaks some of my assumptions.
This is my understanding:
The device driver could only query for certain physical addresses of the target device. What they could do is map these far far away physical addresses to virtual addresses and then access the virtual address.
They could NOT re-map the physical address (MMIO address themselves), the only one who could do this is either Windows or UEFI Firmware by using Intel VT-d tables (is there any other way?)
Right now, we have the read/write into physical memory using !eb or !db commands:
https://docs.hyperdbg.org/commands/extension-commands/e
These commands check the validity of the address before writing into it. The way that we check it is by using the function I posted above.
Now, the problem is, assuming someone wants to create a TLP packet for a PCIe device by using '!eb' function and writing into the physical address (MMIO Address). If we check it with the above function, it says that the address is invalid; however, the address is a valid MMIO physical address, which we incorrectly avoid writing to it since our validity function says it's not valid.
Now the question is, how we should check whether the physical address is valid or not?!eb, !ed, !eq (edit physical memory) | HyperDbg DocumentationDescription of '!eb, !ed, !eq' commands in HyperDbg.
-
Interesting. I didn't realize it's because of that. 👍
-
There is no point thinking about TLPs because it is not programmable from the CPU anyway.
-
Think of PCI BARs - you can literally set any system address there, it is designed to be that way.
-
Also, what you described also doesn't cover the case when the firmware decided to map BARs to a farfaraway system address and Windows driver would use it later on
-
Let's skip VTd here for simplicity as well
-
In fact I usually disable it because I don't want to emultate VTd device, while I still need it for transport drivers
-
Well, isn't like this that writing into certain MMIO regions (PCIe BARs) will cause the CPU's PCIe root complex to create TLP packet for the endpoint devices? 🤔
-
It will, what I'm saying is you can't manually craft TLP packet with system address or something
-
from CPU*
-
👍
-
Interestingly, Linux reorders PCI resources to make MMIO ranges compact. So Linux BAR mappings are likely to be always different compared to what the firmware set up
-
It is debatable which approach is better. Linux doesn't trust the firmware and tried to follow the PCI spec. Windows trusts the firmware, and firmware does whatever it needs to do for the platform to perform better - PCI here is just a high level abstraction for lower level platform protocols and buses, so it is up to a vendor to decide what is better for the platform.
-
Just curious to know, how? The only way that I know is through VT-d. What do they change to reorder these PCIe resources? 🤔
-
PCI BARs
-
PCI bridge resource regions as well
-
Ah, you mean through PCI CAM
-
or ECAM
-
Got it
-
No, PCI BARs
-
Not sure if I understand it. PCIe BARs are configured through PCIe CAM or ECAM. Isn't it like this?
-
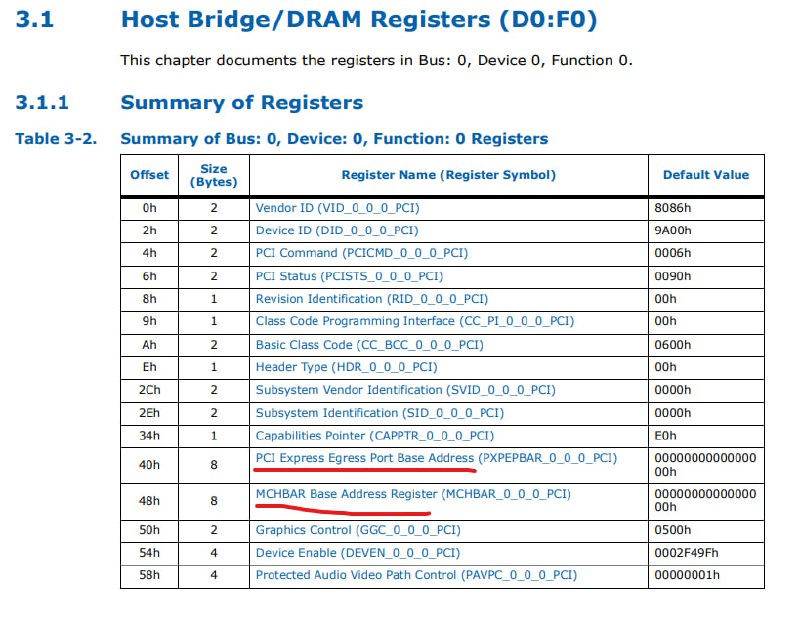
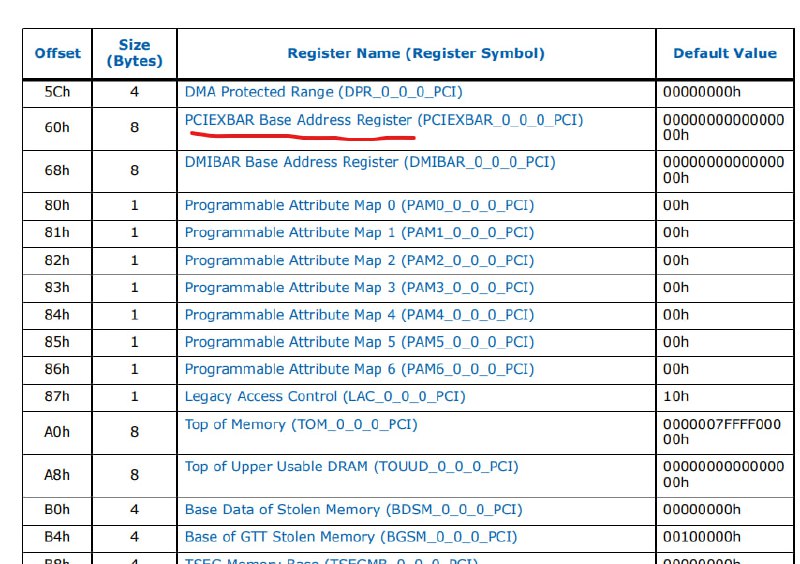
PCI headers reside in ECAM, BARs reside in PCI headers, point to any DMI-decode system address
-
Even the system reserved address ranges are configurable:
-
Those are initialized and locked in firmware (cpudxe)
-
This is by the way how you set ECAM base address
-
Yes, exactly.
-
I think I got it.
-
Thanks
-
No problem!
- 21 July 2025 (3 messages)
-
[discord] <rayanfam> [reply]: I added the support for the addresses above 512 GB to HyperDbg:
-
[discord] <rayanfam> https://github.com/HyperDbg/HyperDbg/pull/533Added support to MMIO ranges above 512 GB by SinaKarvandi · Pull Request #533 · HyperDbg/HyperDbg
Support MMIO above 512 GB
-
[discord] <rayanfam> If you have a better (more efficient) implementation, feel free to change it.
- 22 July 2025 (8 messages)
-
[discord] <unrustled.jimmies> [reply]: Thanks for adding the change.
This way is more efficient since it avoids the ept violation + invept in the first place. As for creating the 511 * 512 block of PML3s instead of reusing the same page, its only 2mb - 4kb, shouldn't really matter.
As for `PML3TemplateLarge.MemoryType = MEMORY_TYPE_UNCACHEABLE;`, can some devices use a different memory type? eg GPU using WC for their frame buffer mmio address. -
This is a bit complicated. Devices might use cached memory for mmio sometimes, but MTRRs should help you with initial caching hint. The other problem I totally forgot to mention is you probably want to use 4kb EPT pages for mmio. It may not work otherwise. Sorry, I completely forgot to mention that.
-
The ideal version of EPT coverage is using 4kb pages for known device mmio and large/huge pages for unused physical address space to save memory for EPT page tables.
-
Yes, but the only caveat is that we are consuming 2MBs of memory by using this approach which I think it's acceptable.
-
Thanks for adding these information. Just curious to know, what will happen if we set all of the out of range (above 512GB) memory to Uncacheable? Is it just about the performance or will it have any impact on the target device which might cause a crash?
-
Generally it’s a performance loss. I’ve known couple of devices that might machine check, but it would be considered as errata.
-
Joined.
-

- 23 July 2025 (48 messages)
-
-
I'm happy to announce that @HyperDbg v0.14 is released!
This version includes HyperEvade (beta preview), fixes Win11 24H2 compatibility issues & adds multiple timing functions to the script engine (Special thanks to Bjorn and all contributors).
Check it out: https://github.com/HyperDbg/HyperDbg/releases/tag/v0.14
More info on HyperEvade: https://github.com/HyperDbg/slides/blob/main/2025/DEBT2025/hyperevade-ecoop2025-debt.pdf
Microsleep function:
https://docs.hyperdbg.org/commands/scripting-language/functions/timings/microsleep
and RDTSC/RDTSCP:
https://docs.hyperdbg.org/commands/scripting-language/functions/timings/rdtsc
https://docs.hyperdbg.org/commands/scripting-language/functions/timings/rdtscp
Thanks to Tara for making this painting for us (it's not AI-generated). -
This one was crazy:
https://x.com/0Xiphorus/status/1948062027156426947 -
I see simple 'if' 'else' compiler bugs dues to the MSVC optimizations on HyperDbg.
-
Which one exactly?
-
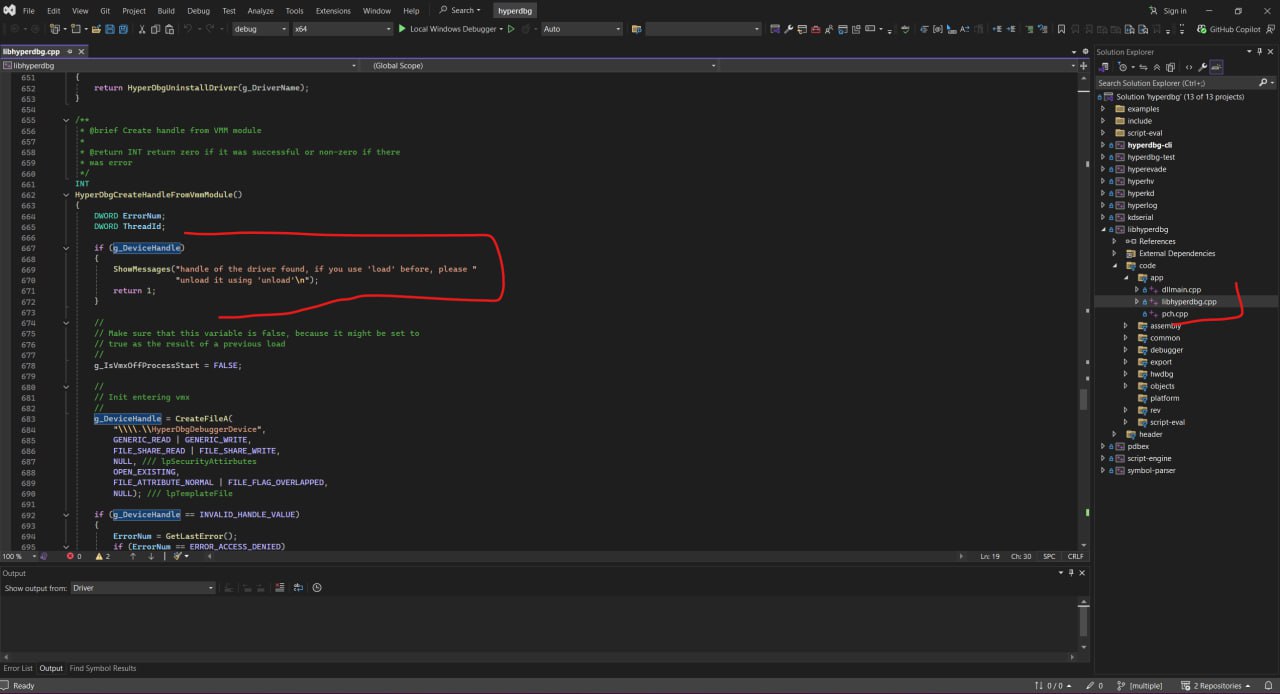
On Visual Studio 17.14.8 and 17.14.9 (Latest) if you use the user-mode optimization for 'libhyperdbg.dll', for this simple line of code, even though g_DeviceHandle is null, still it goes through the 'if' statement. Even initializing this variable doesn't help.
-
I even print the 'g_DeviceHandle' as an unsigned integer inside this 'if' statement and it shows 0, while the if statement is still triggered.
-
Hehe, I'm lucky that I skip major MSVS versions
-
It's like very basic C statement that fails. It seems that others also encountered this issue:
https://x.com/rpcs3/status/1946069204282565100 -
But that's effed up, for real
-
What asm does it produce? Still can't find bug details
-
I didn't check the ASM.
-
But to reproduce it, you can simply git checkout to this commit:
https://github.com/HyperDbg/HyperDbg/commit/9dbfebd5b00f47a19894c971a15d5418abc8521fv0.14 · HyperDbg/HyperDbg@9dbfebdMerge pull request #534 from HyperDbg/dev
-
And build it in the 'release' mode.
-
Then loading HyperDbg, gives a very basic C compiler error.
-
Is there a binary available? I don't have a set up for building rn. Don't worry if it's too tedious to get one
-
It is an example of the HyperDbg with this error:
-
Make sure to download it, I'll remove it in a bit to avoid adding a file in the group archive.
-
Done
-
[discord] <unrustled.jimmies> [reply]: me always having visual studio open so it never updates looks like it saved me from these versions.
-
That's a good idea, but for us, we always need to have the latest version of VS since we have to discover and fix these kinds of issues before HyperDbg users encounter them. Other than that, for the release of HyperDbg, binaries we use GitHub actions. They usually have the updated version.
-
Hey man, I checked the generated asm and I don't see any optimization bugs here:
-
Symbol mapping may be inaccurate in release builds
-
There must be something else
-
Like what? Heap corruption? 🤔
-
Maybe more like a race condition, since it is a public external variable
-
We taught about heap corruption but honestly, this bug also triggered with a simple printf.
-
Do you use driver verifier btw?
-
It's been a long time that we didn't use it
-
Driver verifier would catch mem corruptions on the spot
-
But this one is a user mode bug, does it work with user mode too?
-
Oh, sorry, I missed that
-
Not sure if application verifier helps here
-
But worth a try anyway
-
Application verifier is an alternative to the driver verifier in user mode?
-
Yeah, sort of. It just depends on a heap allocator being used
-
Great. I'll test it and if it finds anything I'll let you know.
-
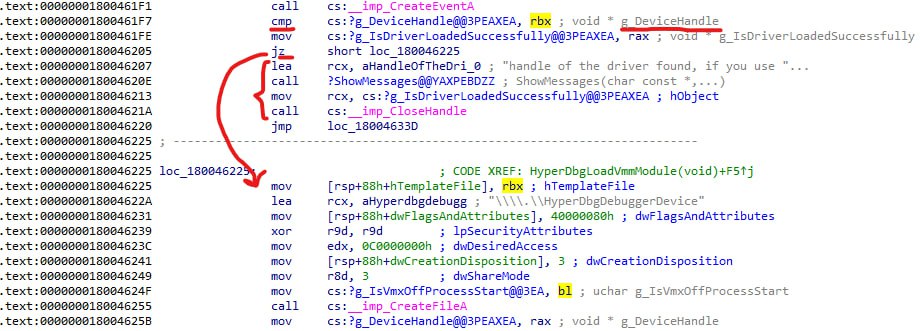
[discord] <unrustled.jimmies> [reply]: Doesn't look like its a bug in msvc. In the optimized build, rbx is getting clobbered out of band with the AsmVmxSupportDetection call it looks like but msvc still thinks its 0 at the point of comparison so it uses that to cmp device with 0x0. In the unoptimized build, its comparing the memory location to 0x0 directly.
for all of your custom written assembly, make sure you either write it like a real function with the prologue or epilogue manually or at least save/restore the non volatile registers (in this case it was tricky since rbx was getting clobbered by cpuid behind the scenes).
https://cdn.discordapp.com/attachments/962350355839066130/1397709841673486446/Screenshot_2025-07-23_141845.png?ex=6882b63a&is=688164ba&hm=6fd18571cdc714852ec775e8a7b084fe591c553733294045034e39a7fdebfc14&
https://cdn.discordapp.com/attachments/962350355839066130/1397709842088591393/Screenshot_2025-07-23_142605.png?ex=6882b63a&is=688164ba&hm=199b4eb5763c1a20e9ca804161982e086ec5598d9732d2d52861229ceb5680aa&
https://cdn.discordapp.com/attachments/962350355839066130/1397709842520477767/before.png?ex=6882b63a&is=688164ba&hm=5834ba09daa7f16941a707857946c660903804f03edca4e2519aa5d70782da8a&
https://cdn.discordapp.com/attachments/962350355839066130/1397709843045027841/after.png?ex=6882b63a&is=688164ba&hm=ff2e04472cdce7f3a59035eb441eb0082c498a1a51c2a99512f7b1770df79398& -
[discord] <honorary_bot> Nice catch man. Yeah, handcrafted assembly does require home space at least.
-
[discord] <unrustled.jimmies> using x64dbg to debug hyperdbg 🙂
-
Oh, great. It would be best if you could send a PR to fix it too.
-
I think it's just one function that we wrote here in assembly, but since you spent a bit of time debugging it, it's probably better you fix it.
-
I promise I won't fix it before you again (like last time). 😜
-
[discord] <unrustled.jimmies> [reply]: Yep ill take a look at this but this is a good opportunity to go over all the hand written assembly just to make sure its not silently happening anywhere else and working by chance.
-
Sure. I'll check it too. It would be best if you could check other assembly codes as well, so we both go through it and hopefully we won't miss anything together.
-
There are not that much assembly codes in HyperDbg. Specially, in user mode, I think we only have one or two. 🤔
-
This bug actually reminded me that I had the same bug once. I assumed that home space is only used for saving function parameters and I could skip it for a small function that doesn't even touch memory. I was wrong, optimizing compiler uses home space however it wants. And the corruption was wild - I was lucky to corrupt the local APIC ID field of a neighbour virtual CPU, which was supposed to be a read only field.. Pheww
-
[discord] <unrustled.jimmies> [reply]: yeah, the best case scenario is a crash. worst case, it works.
- 24 July 2025 (3 messages)
-
Is there a blog or example of hyper-V bypassing anti-cheat detection?
-
@HughEverett boss
-
Hey,
Just to clarify, I'm not working in the anti-cheat area myself. Also, this group is focused on HyperDbg and hypervisor-related topics. Let's try to keep the discussions on-topic to benefit everyone here. Appreciate your understanding! - 26 July 2025 (3 messages)
-

-
@t0r0_ru hi friend trying to reach you urgent for a project. Can you please reply me PM
-
- 27 July 2025 (25 messages)
-
[discord] <whosawhosawhatnow> What's the correct way of doing kernel-mode debugging with HyperDbg? I've been following the official documentation and I have set up a VMWare instance that I'm able to connect to, via HyperDbg. But I'm unable to set breakpoints or hooks at all, for some reason.
```
0: kHyperDbg> !epthook nt!ExAllocatePoolWithTag
err, couldn't resolve error at 'nt!ExAllocatePoolWithTag'
...
0: kHyperDbg> bp nt!ExAllocatePoolWithTag
the user-mode debugger in VMI Mode is still in the beta version and not stable. we decided to exclude it from this release and release it in future versions. if you want to test the user-mode debugger in VMI Mode, you should build HyperDbg with special
instructions. But starting processes is fully supported in the Debugger Mode.
(it's not recommended to use it in VMI Mode yet!)
```
Is it just not possible to do kernel debugging with a virtual machine? -
Hey,
We encountered several issues with the new Visual Studio optimizations. Some of them have been fixed (thanks to the members of this group who helped us identify the issues), while others remain unresolved. First, since we’ve changed the optimization levels multiple times, please make sure to run git pull and use the latest version of HyperDbg (v0.14.1, which was released a while ago). It should resolve your problem. If the issue still persists, please report it here. As a temporary workaround, you can build HyperDbg using the 'debug' configuration (without optimization). -
[discord] <whosawhosawhatnow> Thank you, v0.14.1 seems to have fixed the issue. 👍
-
Yes, but I noticed after around ~1 hour, it randomly halts the system in the 'release' builds, but in case of the 'debug', I couldn't reproduce the same behavior after 10 hours. So, I assume still there might be similar errors/bugs.
-
[discord] <whosawhosawhatnow> I see. I'll try a debug build later if I start seeing the same issue.
-
👍
-
[discord] <unrustled.jimmies> [reply]: What do you mean when you say `halts`. It executes the `hlt` instruction on all cores then never makes progress from there or the system freezes?
-
[discord] <unrustled.jimmies> Do you have a build where that repros? i can try to run it and see what i find.
One thing i can think of (i however believe this is being done on purpose for performance reasons) is we also aren't saving the SIMD registers and restoring them in the vmexit and if they are used (for example in a memcpy etc) during the vmexit, it could also be over-ridden.
https://github.com/HyperDbg/HyperDbg/blob/5d8d3ca524a95d4987d8ff2eb055f773fccfd5d3/hyperdbg/hyperhv/code/assembly/AsmVmxOperation.asm#L65HyperDbg/hyperdbg/hyperhv/code/assembly/AsmVmxOperation.asm at 5d8d3ca524a95d4987d8ff2eb055f773fccfd5d3 · HyperDbg/HyperDbgState-of-the-art native debugging tools. Contribute to HyperDbg/HyperDbg development by creating an account on GitHub.
-
No, it's not about the 'hlt' instruction. It just randomly halts without any response (VM-exit) and didn't find a definite way of reproducing it but it happened to me once after 1 hour. I couldn't reproduce it for now to further investigate it but you are right about these XMM register instructions. They were previously proven to be problematic and because of this we disabled performance optimizations on hyperhv.dll long time ago.
-
Anyway, just to quickly check it with you. Did you test HyperDbg with the latest patch that covers the entire EPT address range? I tested on a meteor lake with a regular MMIO address space (less than 512 GB) and it works fine for almost 24 hours of testing. After that I tested it on a meteor lake machine that uses MMIO addresses above 512 GB and I noticed even though the target devices start to work properly (which means our patch is working), but after 3 or 4 minutes, Windows crashes in different random locations. I investigate it but I couldn't find a definite pattern to know what's going wrong. Do you also have the same problem with your machine that uses MMIO addresses above 512 GB?
-
[discord] <unrustled.jimmies> [reply]: unfortunately, even with the `/kernel` msvc flag and optimizations turned off, it can still use/link with implementations with those registers being used. eg `memset` in hyperhv which is called in the vmx exit handler for some operations.
https://cdn.discordapp.com/attachments/962350355839066130/1399154388001620038/Screenshot_2025-07-27_151205.png?ex=6887f791&is=6886a611&hm=d90d17c89cb0a6698ed6a1ecda4be6dee78f5efe16046a070b9e01ff9041e69d& -
[discord] <unrustled.jimmies> [reply]: I can let this run for a bit. will let you know.
-
So, you mean we should inevitably save and store XMM registers on VM-exits?
-
👍
-
@honorary_bot do you also have any comment on this?
We comment these lines for performance reasons:
https://github.com/HyperDbg/HyperDbg/blob/5d8d3ca524a95d4987d8ff2eb055f773fccfd5d3/hyperdbg/hyperhv/code/assembly/AsmVmexitHandler.asm#L20
Other than these XMM registers, are there anything else (any other registers) that we should save and restore on each VM-entry/exit?HyperDbg/hyperdbg/hyperhv/code/assembly/AsmVmexitHandler.asm at 5d8d3ca524a95d4987d8ff2eb055f773fccfd5d3 · HyperDbg/HyperDbgState-of-the-art native debugging tools. Contribute to HyperDbg/HyperDbg development by creating an account on GitHub.
-
Hey man!
I'm not sure if we've discussed that before, but I definitely shared https://pulsedbg.com/codequal.html with you. One of the things I described there is the issue with XMM registers. I chose not to use them since saving and restoring them is a performance penalty. You can't really avoid XMM usage if you're building x64 binaries with MSVS since using XMM registers is a part of MS x64 fastcall ABI. I described the way I do quality control in that article as well as some more problems that I encountered in the past.
As for the commit, movaps does require an aligned stack pointer, so hoping you make sure it always is. Other than that - why is there sub rsp, 0x100 in the end of the AsmVmexitHandler function? -
Great. Thanks for sharing. Yeah, you're right, now that I think about it, it's not needed since the instruction after that would be the 'VMRESUME'.
-
[discord] <unrustled.jimmies> [reply]: I just ran it on my system and it worked fine (tested for 30 mins).
-
You mean the system with MMIO address range above 512 GB?
-
[discord] <unrustled.jimmies> yep.
-
And also, which processor generation and Windows version?
-
[discord] <unrustled.jimmies> ArrowLake 285k, Latest windows 24h2.
-
Interesting. Thanks for testing it. I have to go through the meteor lake machine (with MMIO above 512 GB) again to see if I could find the problem. I will notify you in the group if I find the bug.
-
Anyway, an interesting observation I saw yesterday was that Windows starts executing VMCALL instructions on all cores immediately after loading HyperDbg. It seems, they have some routines to detect when a hypervisor is loaded regardless of whether Hyper-V/VBS is running or not.
-
(on bare metal)
- 28 July 2025 (2 messages)
-
[discord] <unrustled.jimmies> [reply]: The only vmcalls i see are the ones that hyperdbg makes upon the launch of each core when i just ran. (did you check what module the guest rip for these vmcalls was in?)
-
Not sure. I think it was within one of the hyper-v modules, but now that I'm thinking of it, I might accidentally get a wrong VM-exit number due to a debugging error. I'll double check, if I could find the module and if it was not mistakenly flagged by me, I'll let you know.
- 29 July 2025 (1 messages)
-
Joined.
- 30 July 2025 (9 messages)
-
Can you support real machines now?
-
Before I tested it, it didn't support it.
-
@HughEverett
-
Hey 👋
HyperDbg supports the bare metal (physical) machine from its very first release. However, the user debugger (in VMI mode) is still under construction:
Right now, it supports starting a process and intercepting the OEP (using HyperDbg's approach, not Windows debug flags) and it also supports reading/editing memory and setting breakpoints. However, other fundamental debugging commands like reading and modifying registers and stepping through instructions are not yet implemented for the user debugger (the kernel debugger has all of the features). -
So, in summary I could say, we had 50% progress on implementing it. It's not yet done but there is no technical barrier at the moment, it's just the matter of implementation and testing.
-
Yes, the user debugger still doesn't work.
-
I need a job as simple as ce.
-
This program is really powerful.
-
Thank you for your efforts.
@hyperdbg / Public archive of HyperDbg Telegram messages.


{kind=link}
{kind=link}
- 04 Jul 2025 (2)
- 05 Jul 2025 (50)
- 06 Jul 2025 (15)
- 07 Jul 2025 (5)
- 09 Jul 2025 (4)
- 10 Jul 2025 (4)
- 13 Jul 2025 (2)
- 14 Jul 2025 (1)
- 15 Jul 2025 (3)
- 16 Jul 2025 (8)
- 18 Jul 2025 (1)
- 19 Jul 2025 (59)
- 21 Jul 2025 (3)
- 22 Jul 2025 (8)
- 23 Jul 2025 (48)
- 24 Jul 2025 (3)
- 26 Jul 2025 (3)
- 27 Jul 2025 (25)
- 28 Jul 2025 (2)
- 29 Jul 2025 (1)
- 30 Jul 2025 (9)