- 02 May 2025 (3 messages)
-
Joined.
-
Joined.
-
Joined.
- 05 May 2025 (4 messages)
-
 [discord] <t0int> Where can i join the telegram group
[discord] <t0int> Where can i join the telegram group -
 HyperDbg
HyperDbgHyperDbg Discussions Group 🪐✨ *** Hardware & Software Debugging and Reversing Infrastructures *** This group is synchronized with #Discord, #Matrix, etc. Source code: https://github.com/HyperDbg/HyperDbg Group Archive: https://tg-archive.hyperdbg.org
-

-
- 06 May 2025 (41 messages)
-
-
the user-mode debugger in VMI Mode is still in the beta version and not stable. we decided to exclude it from this release and release it in future versions. if you want to test the user-mode debugger in VMI Mode, you should build HyperDbg with special instructions. But starting processes is fully supported in the Debugger Mode.
(it's not recommended to use it in VMI Mode yet!) -
the user-mode debugger in VMI Mode is still in the beta version and not stable. we decided to exclude it from this release and release it in future versions. if you want to test the user-mode debugger in VMI Mode, you should build HyperDbg with special instructions. But starting processes is fully supported in the Debugger Mode.
(it's not recommended to use it in VMI Mode yet!) -
this why?
-
Doesn't it support using ivm mode in local machine?
-
@HughEverett
-
Do you know why?
-
I can't use the local computer.
-
If you want to debug a process (step through its instructions or start it from entry point or put breakpoints), you need to use HyperDbg in the debugger mode, not VMI mode.
-
Vmi mode can't even start a process?
-
No matter what command I type, it always appears this prompt.
-
Or did I not enter the correct instructions? Do you have any examples?
-
HyperDbg doesn't use DEBUG FLAGs to start a process (to further enhance its transparency) instead it uses hypervisor tricks to intercept the execution of the first instruction. That's why it's not that easy to implement the similar approach in the VMI mode. Right now, it fully support process creation in the debugger mode.
-
You need to see open security training course on HyperDbg. Plenty of examples for starting the process are there:
https://ost2.fyi/Dbg3301
Or in YouTube:
https://www.youtube.com/watch?v=RDlp0PCFgxI&list=PLUFkSN0XLZ-kF1f143wlw8ujlH2A45nZYDebuggers 3301: HyperDbgThis class teaches you how to use HyperDbg, a virtualization-based debugger.
-
-
-
I don't understand, what are the special instructions?
-
-
-
-
Yes, I'm doing it, thank you.
-
-
So that means it doesn't work?
-
I want to make it my own epthook.
-
But you said it doesn't support local mode?
-
Is that right? It doesn't support local mode?
-
-
-
-
It has so many problems. So what is its meaning?
-
😂
-
-
I think it should work if it is in a virtual machine.
-
I will try to compile the code again,
-
-
OK
-
This might be bug with HyperDbg. Did you also have the same problem with running it from host?
-
Because I see sometimes VMWare doesn't properly handle serial connections over two VMs. But, Guest to host is perfectly fine.
-
If you want to use HyperDbg in a full-featured mode, you need to run it in the Debugger Mode.
-
VMI Mode contains all the features of the Debugger mode except you cannot put breakpoints, break to debugger in case of triggering an event, and step through the instructions. All of these capabilities are available in the Debugger Mode (not local VMI mode).
-
Other than that, everything is the same (e.g. you can scripts and trigger custom scripts in case of events) in the VMI Mode.
- 07 May 2025 (3 messages)
-
Joined.
-
@HughEverett I use vmi mode on my local machine, and it can't even use the startup command.
-
@t0r0_ru Did you find an alternative?
- 08 May 2025 (6 messages)
-
I tried the emulator https://www.serial-over-ethernet.com/downloads.
This emulator can create a virtual port.
Without success...Download Serial to Ethernet Connector for Windows and Linux OSLatest version of Serial to Ethernet Connector is available for download on Windows and Linux OS
-
-
-
Yes. I told you earlier, the '.start' command only works in Debugger mode (not in VMI mode).
-
HyperDbg communicates with IO ports for serial debugging. I'm not sure if the interface of these serial emulators are the same.
-
For example, if you have a PCIe card to serial, it doesn't work with HyperDbg because the interface of communication is over PCIe BARs or custom PCIe IO ports which HyperDbg is not aware of.
- 12 May 2025 (2 messages)
-
-
👍
- 13 May 2025 (5 messages)
-
hi everyone, how to build the hyperdbg-cli support --debugger args. I want to attach a process in VMI Mode.
-
The support for attaching in the VMI mode is not stable yet. You should use HyperDbg in the Debugger mode for switching into processes.
-
thank your for your reply. How to operate it?
-
My application run in windows10. How to switching to Debugger mode?
-
You need to follow steps mentioned in this page:
https://docs.hyperdbg.org/getting-started/build-and-install
If you prefer to see these steps in a video, you should check:
https://youtu.be/MDZ9zYfqo50
And here for attaching to HyperDbg over the Debugger Mode:
https://docs.hyperdbg.org/getting-started/attach-to-hyperdbg/debugBuild & Install | HyperDbg DocumentationThis document helps you to build and install HyperDbg
- 14 May 2025 (4 messages)
-
I got this error when i use debugger model.
-
-
The equivalent to attaching to a process in the debugger mode is the '.process' or the '.thread' command:
https://docs.hyperdbg.org/commands/meta-commands/.process.process, .process2 (show the current process and switch to another process) | HyperDbg DocumentationDescription of '.process, .process2' commands in HyperDbg.
-
got it.thank your very much
- 17 May 2025 (64 messages)
-
[discord] <unrustled.jimmies> I disable hyperv/hvci, boot using efiguard, disable dse and then load hyperdbg but i get exception on invalid stack. Anything im missing (will look into the logs later but just wanted to check if anyone has any ideas of what i could be doing dumb or if there are any logs generated i can look at)
-
[discord] <unrustled.jimmies> Got the stack trace by opening up the minidump in windbg
```
ffffc181`e70a55e8 fffff803`e9e73a3d : 00000000`000001aa ffffae8f`989aee60 00000000`00000003 ffffc181`e70a58d0 : nt!KeBugCheckEx
ffffc181`e70a55f0 fffff803`e9c98e83 : 00000000`00000000 ffffae8f`989aecd0 00000000`00000000 00000000`00000001 : nt!RtlpGetStackLimitsEx+0x5d
ffffc181`e70a5640 fffff803`e9ddd501 : ffffae8f`989aeaf0 ffffc181`e70a5dd0 ffffae8f`989aeaf0 fffff780`00000708 : nt!RtlDispatchException+0xe3
ffffc181`e70a58a0 fffff803`ea0a52b2 : cccccccc`ccccffff 6c894808`245c8948 57182474`89481024 57415641`55415441 : nt!KiDispatchException+0xac1
ffffc181`e70a5fb0 fffff803`ea0a5280 : fffff803`ea0b913e 00000000`00000000 00000000`00000000 00000000`00000000 : nt!KxExceptionDispatchOnExceptionStack+0x12
ffffae8f`989aeae8 fffff803`ea0b913e : 00000000`00000000 00000000`00000000 00000000`00000000 00000000`00000000 : nt!KiExceptionDispatchOnExceptionStackContinue
ffffae8f`989aeaf0 fffff803`ea0b139b : ffffae8f`98836000 00000000`00000003 ffffae8f`989aee88 fffff803`a5d71607 : nt!KiExceptionDispatch+0x13e
ffffae8f`989aecd0 fffff803`a4470343 : ffffae8f`00000003 00000000`00000d01 00000080`00203001 00000000`00000001 : nt!KiBreakpointTrap+0x35b
``` -
[discord] <unrustled.jimmies> ```
ffffae8f`989aee60 ffffae8f`00000003 : 00000000`00000d01 00000080`00203001 00000000`00000001 fffff803`a4482a30 : hyperhv+0x10343
ffffae8f`989aee68 00000000`00000d01 : 00000080`00203001 00000000`00000001 fffff803`a4482a30 fffff803`a4482a10 : 0xffffae8f`00000003
ffffae8f`989aee70 00000080`00203001 : 00000000`00000001 fffff803`a4482a30 fffff803`a4482a10 00000000`00000407 : 0xd01
ffffae8f`989aee78 00000000`00000001 : fffff803`a4482a30 fffff803`a4482a10 00000000`00000407 fffff803`9c2b630f : 0x00000080`00203001
ffffae8f`989aee80 fffff803`a4482a30 : fffff803`a4482a10 00000000`00000407 fffff803`9c2b630f 00000000`00000d82 : 0x1
ffffae8f`989aee88 fffff803`a4482a10 : 00000000`00000407 fffff803`9c2b630f 00000000`00000d82 00000080`0020301c : hyperhv+0x22a30
ffffae8f`989aee90 00000000`00000407 : fffff803`9c2b630f 00000000`00000d82 00000080`0020301c 00000000`00000000 : hyperhv+0x22a10
ffffae8f`989aee98 fffff803`9c2b630f : 00000000`00000d82 00000080`0020301c 00000000`00000000 fffff803`a44761c3 : 0x407
ffffae8f`989aeea0 00000000`00000000 : 00000000`00001c20 00000000`00000001 00000000`00000002 00000000`00000000 : USBXHCI!Bulk_Stage_MapIntoRing+0x6df
``` -
[discord] <unrustled.jimmies> hyperhv+0x10343 is this, not sure why this would trigger an exception
```
180010343 32c0 xor al, al {0x0}
```
Actually looks like this is the problem, since this is the stack trace 10343 is the next addr to go to so i looked at 10342 and saw
```
1800102e7 if (!(uint32_t)sub_180009a40(*(uint32_t*)((char*)arg1 + 0x30), var_18, temp0))
1800102ec {
1800102fb int64_t var_20 = *(uint64_t*)((char*)arg1 + 0x40);
180010300 int32_t var_28 = 0x407;
18001030f void* const var_30 = "EptHandleEptViolation";
180010336 sub_180009780(3, 1, 1, 1, "[!] Error (%s:%d) | Err, unexpec…");
180010342 breakpoint();
``` -

-
-
What is the running environment? Is it a baremetal machine or VMware workstation?
-
It seems that it's because of an unexpected EPT violation. But why EPT violation? Did you run any command like !monitor or !epthook?
-
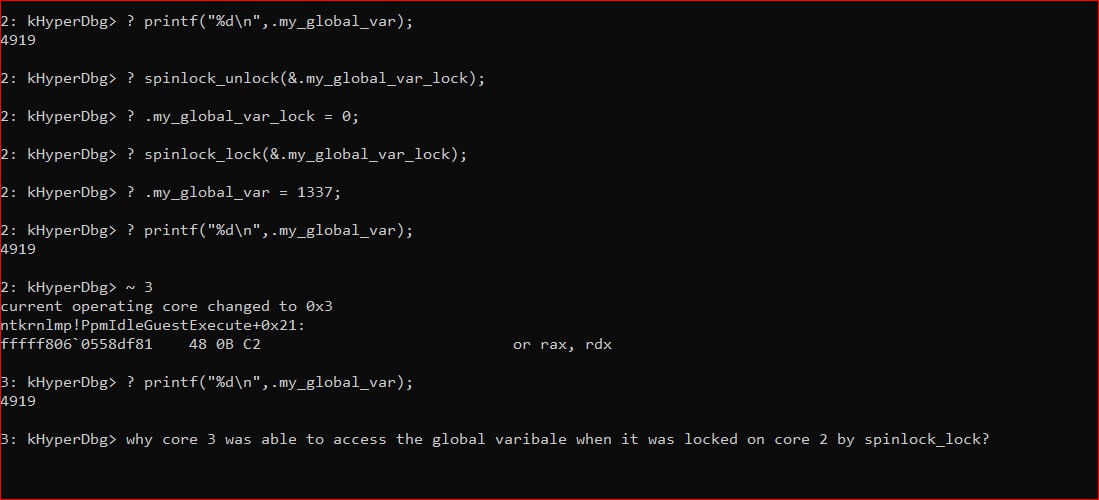
I don't understand the logic behind this code. Adding _lock to a variable name doesn't have to do anything with locking it from modification by another core.
-
[discord] <unrustled.jimmies> [reply]: It could be my drivers, i use Logi with default windows usb drivers since i saw `USBXHCI!Bulk_Stage_MapIntoRing+0x6df` in the stack trace, then installed Logi+ Native drivers then the stack trace changed to `igdkmdn64+0x4447e1` then i updated intel drivers then it changed to `nvlddmkm+0xd710a3` kicking off the EPT violation. Unfortunately im on the latest nvidia drivers so.
Not sure why its kicking off ept violations since i didnt set anything up, i just did `.connect local` and `load vmm` and thats when it BSOD's. Computer is new as well. -
[discord] <unrustled.jimmies> Running env is baremetal windows 11
-
 @HughEverett do you build EPT pages for the whole physical address space? My random guess would be that those dirvers use MMIO which is remapped above the top of addressable dram memory and possible that area is not covered by your EPT
@HughEverett do you build EPT pages for the whole physical address space? My random guess would be that those dirvers use MMIO which is remapped above the top of addressable dram memory and possible that area is not covered by your EPT -
Can you try setting up bios settings to "Use above 4g decode - no and/or remap 4g - no" just to test this theory?
-
This is a bad advice for setting up your bios params, this is just for testing
-
[discord] <unrustled.jimmies> Yep, i can try that now.
-
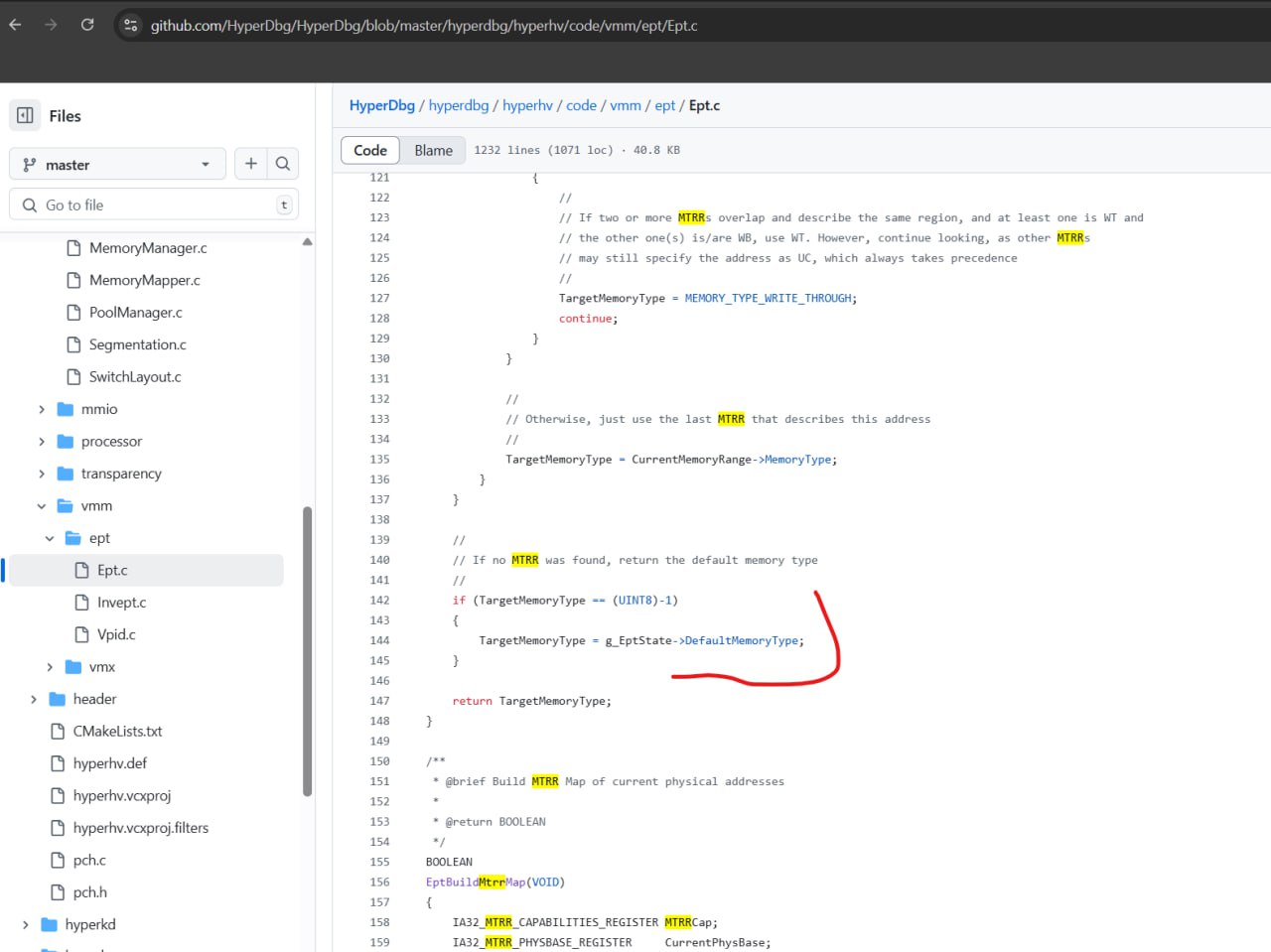
Well, we build everything based on available MTRRs for the entire address space of MTRRs. Does the remapping change it at some point?
-
I mean, is it like that remapping causes to create something out of the range of MTRRs?
-
MTRRs don’t cover the whole physical address space, there is a def one, right? The regions that are not described on MTRRs just default to MTRR def MSR.
-
def one?
-
Default one
-
Something something DEF MSR, don’t remember the name now
-
You can point your MMIO BAR to almost anywhere on the physical address space. If there is no dram, it will just go to DMI decode
-
The only thing that limits it is a width of a physical address
-
-
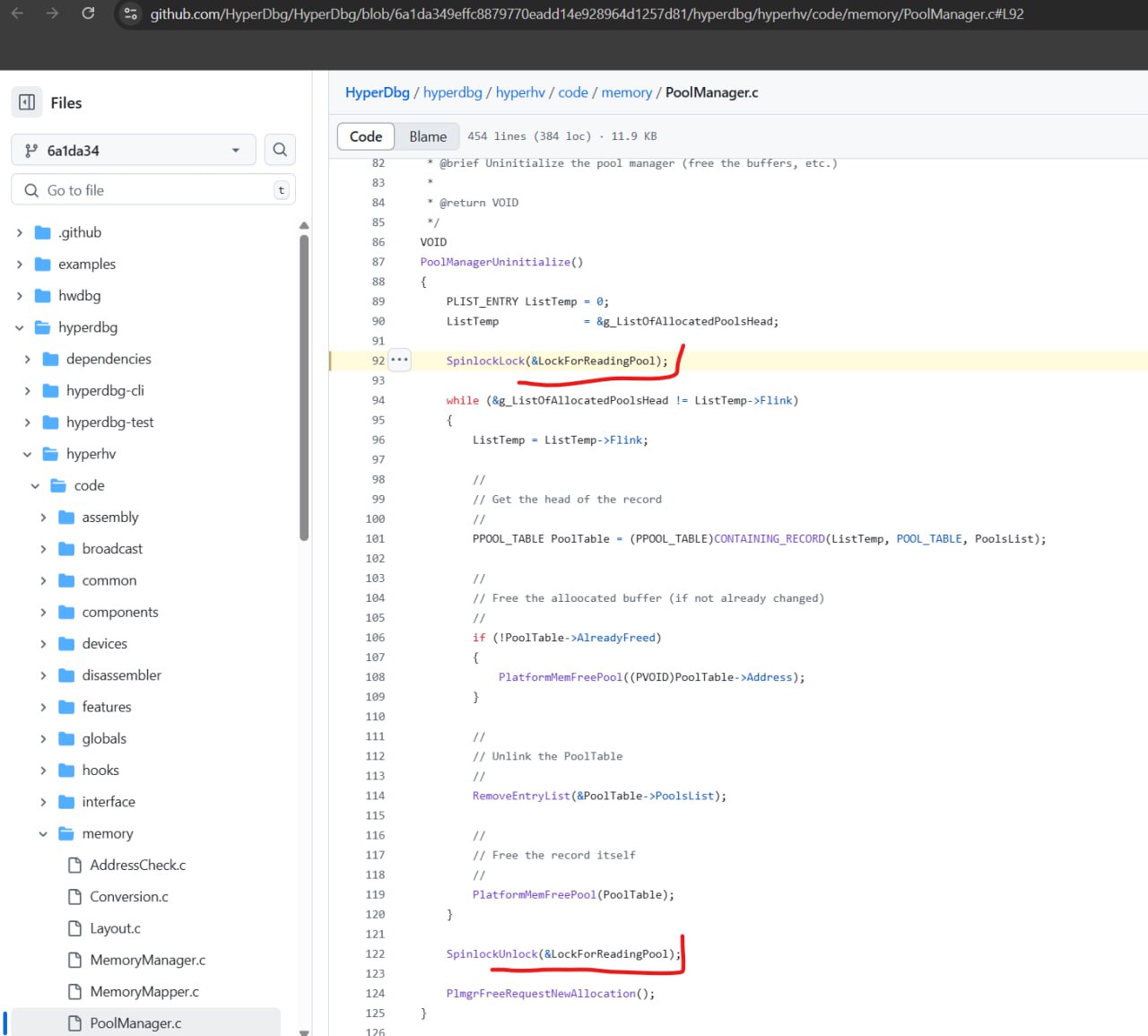
This is the entire MTRR logic of HyperDbg: https://github.com/HyperDbg/HyperDbg/blob/6a1da349effc8879770eadd14e928964d1257d81/hyperdbg/hyperhv/code/vmm/ept/Ept.c#L156HyperDbg/hyperdbg/hyperhv/code/vmm/ept/Ept.c at 6a1da349effc8879770eadd14e928964d1257d81 · HyperDbg/HyperDbg
State-of-the-art native debugging tools. Contribute to HyperDbg/HyperDbg development by creating an account on GitHub.
-
And since physical address space is sort of huge, you can save some memory for EPT tables using large or even huge EPT
-
Here is a very basic example of using a spinlock in a C code. The same concept applies to HyperDbg's script engine spinlock function (you need to use it like this.).
-
So, it's like you put a spinlock and lock it, another thread (or core) also needs to lock the spinlock and because it's already locked, the new thread couldn't lock it and it prevent the modification by two (or more) threads or cores.
-
Hypervisor From Scratch – Part 8: How To Do Magic With Hypervisor!
We write about Windows Internals, Hypervisors, Linux, and Networks.
-
Hi thanks a lot for the reply and explanation. i understand now that instead of locking just a variable name there should have been set of instructions executing on the variable while is locked in particular code region. And while code portion is executing on the spinlocked variable on a core(read or write), no other core can access the locked variables concurrently.
Something like mutex or critical-region in user mode.Right?
Really appreciate your replies. -
-
Yes, spinlock is also an operating system concept similar to mutex or semaphore to protect the critical region.
-
[discord] <unrustled.jimmies> [reply]: I am on the msi-pro z890-p, couldnt find an option to disable the above 4gb decoding (i disabled resizable bar and still the same issue).
I created a windows 11 vm on that same pc and ran hyperdbg inside the vm and it worked properly.
So i think the issue is def some device is using an address outside what hyperdbg maps into ept. I will try to disable some devices and see whats needed to get hdbg to work on the non vm pc. -
Is it arrow lake?
-
[discord] <unrustled.jimmies> yeah, its the 285k
-
nice cpu ;) it's weird theres no above 4g decode setting though, probably because of the oem bios
-
We can test our theory in another way if you're interested
-
[discord] <unrustled.jimmies> Yeah, willing to try other methods as well, i just changed my crash type type to full kernel and was gonna look into that rn (earlier one was just a minidump).
-
You could try loading the pulsedbg hypervisor (though you would have to temporarily disable secure boot and vt-d). If you're interested, I can share a fresh build of it.
-
It has a EFI loader, so it boots before the operating system
-
[discord] <unrustled.jimmies> sure i can try that, already had to disable sb for efiguard so i can try this as well.
-
-
if it progresses to load the operating system, then it's likely a ept problem on hyperdbg
-
i'm also very curious because i havent tested it on arrow lakes yet, just meteor lake
-
[discord] <unrustled.jimmies> It says load error insufficient resources then proceeded to the normal windows boot
https://imgur.com/a/iTNv2oQLinkDiscover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and so much more from users.
-
Wow, your configuration has indeed some unique features.
-
how much ram do you have?
-
[discord] <unrustled.jimmies> 64gb
-
I see, I need to increase the memory limit for 64 gb ram. Lemme rebuild and reupload it
-
[discord] <unrustled.jimmies> got it.
-
I've re-uploaded the binary. Could you try once more?
-
Also, I've uploaded a configuration utility to play with the settings https://pulsedbg.com/files/test/PulseConfig.exe
-
[discord] <unrustled.jimmies> yep lemme retry
-
[discord] <unrustled.jimmies> Yeah something seems to just be wrong,
pulsedbg is stuck on loading core https://imgur.com/a/DBvLer5 (been a couple mins).
I also compiled and tried https://github.com/jonomango/hv and it also freezes the pc when i start the sc.
Weird thing is hyperdbg in the vmware vm works on the same pc (and im sure these will as well).LinkDiscover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and so much more from users.
-
It's actually quite clear why VMWare works - it emulates VMX with a predefined reduced feature set
-
Whereas the real hardware has some.. feature which we'll need to figure out
-
Thanks for trying! Unfortunately I don't have an Arrow Lake machine to investigate on
-
[discord] <unrustled.jimmies> yep, thanks for helping. i will continue to see what i find on my end.
-
Gosh, I'm looking at the specs for 285k, it has a physical address space of 256 gigs. This is something I would definitely need to test at some point. It might be the culprit, including why PCI ECAM has this layout
-
The default VMCS setup also might be different, since new VMX features being added that are not necessarily backwards compatible with default vmcs settings
-
Many things can go wrong unfortunately
-
What network cards do you have on this pc?
-
[discord] <unrustled.jimmies> From device manager - https://imgur.com/a/ISEZVdDLink
Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and so much more from users.
-
*sigh* realtek. It's unlikely pulsedbg supports it anyway. Sad.
- 18 May 2025 (2 messages)
-
[discord] <unrustled.jimmies> Looks like the nvidia driver is trying to read the address 0xb010230000 which is 756gb (more than the 512gb of ept pages hyperdbg identity maps). I updated hyperdbg to map 1tb instead of 512gb and it no longer bsod's, it just freezes. (probably just vmexits on the same read in an inf loop)
-
[discord] <unrustled.jimmies> ill mess with this a bit more when i can debug the hv using 2 pcs + windbg.
- 19 May 2025 (1 messages)
-
- 20 May 2025 (16 messages)
-
-
Does anyone know how to make hyperdbg support real machines instead of virtual machines?
-
Could you also let me know if you’ve made any progress on that? I suspect my Meteor Lake machine is having issues with HyperDbg — though everything works fine in VMware. Initially, I thought the issue might be related to the difference between performance cores (P-cores) and efficiency cores (E-cores). I'm not entirely sure how they differ in terms of Intel VMX or how a hypervisor might need to handle them differently. Maybe @honorary_bot has any thought on it?
-
I currently don't have an MTL machine anymore. But! I ordered an ARL (Arrow Lake) mini pc and expecting delivery. I was embarrased enough for it not working on 285k so that I will investigate it this week. Maybe I'll spot some core (or maybe firmware) differences that will give you a clue as well.
-
Yes, you can trace all functions (by putting !epthook). Last time I test it by more than 3000 functions and it was fine. Using the '!monitor' and x (execute) parameter is also another option but it's not recommended for a big chunk of memory because it slows down the system due to the fact that you could run only one single instruction each time.
-
HyperDbg support bare metal system in the VMI mode.
-
Great. Thanks.
-
I did have problems with MTL though, but I didn't have a repro for the bugs I encountered. ARL cores are the same as Lunar Lake (LNL) cores, so hopefully fixing ARL will make MTL work as well.
-
[discord] <unrustled.jimmies> [reply]: Yeah i made some progress on this but no fix yet. I compiled a bunch of type 1 vtx hypervisors from github to see if any of them would work and they all seem to be having the same issue so its most likely not just a hyperdbg issue and more of a something changed in arrowlake or my setup issue.
Currently im just trying to remove variables, i have a base hv and i made it map all 256TB of memory to ept to remove that variable and it still freezes as soon as its ran which i couldnt debug. So i updated it to just hypervise 1 processor out of the 24 and it now runs and the pc works for about 30 seconds to 1 minute which is at least debuggable so thats what im messing with right now. -
Hopefully I'll get the same problems on 255K, ASUS firmware. Also very curious about what's going on.
-
I saw one time a vmx implant on a noname chinese mini pc for example
-
So I was not the first hypervisor to be launched on the platform :)
-
[discord] <unrustled.jimmies> [reply]: i dont see the 255k on here https://www.intel.com/content/www/us/en/ark/products/series/241071/intel-core-ultra-processors-series-2.html
did you mean 245k/265k?Intel® Core™ Processors, FPGAs, GPUs, Networking, SoftwareBrowse Intel product information for Intel® Core™ processors, Intel® Xeon® processors, Intel® Arc™ graphics and more.
-
255h, my bad
-
[discord] <unrustled.jimmies> looks like this also has a 3rd type of core compared to the 285k, the `Low Power Efficient-cores`, hope that doesnt mess anything up.
-
Yeah, it’s like MTL, but lion cove. It shouldn’t matter. I can even disable them in bios.
- 21 May 2025 (13 messages)
-
err, the script or assembly code is either not found or invalid. As a result, the default action is to break. However, breaking to the debugger is not possible in the VMI Mode. To achieve full control of the system, you can switch to the Debugger Mode. In the VMI Mode, you can still use scripts and run custom code for local debugging.For more information, please check: https://docs.hyperdbg.org/using-hyperdbg/prerequisites/operation-modesOperation Modes | HyperDbg Documentation
Different Modes of Operation in HyperDbg
-
-
-
👍
-
Yes, you cannot pause the (break) the processor in local debugging (VMI Mode).
-
Well, it depends on what you mean by tracking. Do you want to simply detect if a function is called, or do you want to track the execution path within the function (i.e., which basic blocks it touches)?
-
Hey there. Just got a shiney ARL NUC. And guess what, it worked from the first try. Do you have the latest bios?
-
There is something weird going on with your system..
-
[discord] <unrustled.jimmies> [reply]: Thats good, so its just me. I have the latest bios i can download for my system (booting into bios says its from 3/2025) and drivers as well. Lemme doublecheck.
-
*random complaint*
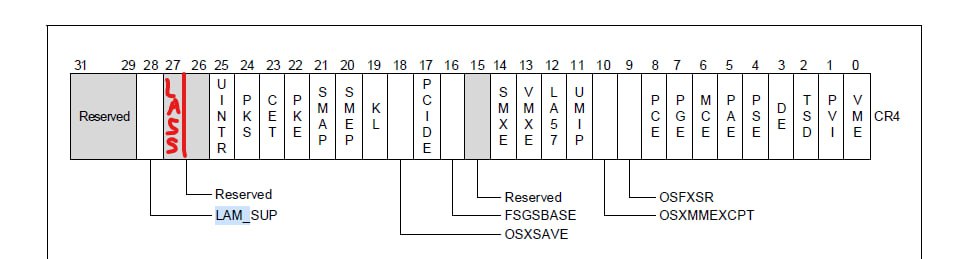
Gosh, I've updated VMX caps table for Arrow Lake CPU. It's the second time I had this problem with Intel SDM. They always forget to consistently update documentation. Last time they forgot to add LA57 bit of CR4. This time I noticed that MSR 489 (Allowed 1 settings for CR4) has 27 bit set. But it is not described in SDM. -
This time they forgot to add LASS bit
-
Gonna have to file a bug tomorrow
-
Btw if any of you guys find any inconsistencies or bugs in SDM, you call me out. I can fix that.
- 22 May 2025 (53 messages)
-
-
You can put !epthook on all of them.
-
I tested it with more than 3000 hooks and it works like a charm. Putting hooks on even more functions should be supported (depending on the execution rate of those functions).
-
Have you tried disabling vt-d?
-
Do you need to modify the source code? It does not support the current code.
-
Joined.
-
[discord] <unrustled.jimmies> [reply]: Yeah i disabled vt-d both when i tried with with pulsedbg, hyperdbg and my test hv.
I noticed MSI has a later bios than the one listed on corsair so i also updated to that one and still the same issue.
I am genuinely stumped as to what the issue could be. Here is a link to my hwinfo log if it helps (vt-d was on when i ran this tho) https://1drv.ms/t/c/866108056c56eba9/EUL6phn0lNJOhtDpmH92SaYBMRE_DsT_MAfP63GxMm0aOA?e=4ngIvw -
Do you happen to have a USB 3.0 debug cable?
-
Or an external Intel Network card? (I remember you had realtek)
-
Looks absolutely normal!
-
[discord] <unrustled.jimmies> [reply]: i dont but i can buy one (this is to allow debugging the cpu even after it freezes right?
-
We could get log output out of PulseDbg at least
-
In the meantime, can you try launching PulseDbg in a single core config? Just disabling hyper-threading and all cores except one?
-
[discord] <unrustled.jimmies> yea, i can try that
-
If it runs, we might guess there is a problem in multicore code
-
[discord] <unrustled.jimmies> [reply]: interesting.
pulsedbg on 1 core says Load Successful but then the system "reboots" (most likely not a full reboot) and on the second time it says VTX Not Available. This looks like a Fast Boot issue, so i disabled that and still on 1 P core enabled, now it boots, pulse dbg says Load Successful then black screen. -
Nice! The first time it attempted to boot the next boot entry which happened to be itself, so it tried loading itself and discovered that vmx is not available (since modified in the hypervisor). So it behaved as expected. Great!
-
Which OS is installed on this machine?
-
[discord] <unrustled.jimmies> latest win11 pro
-
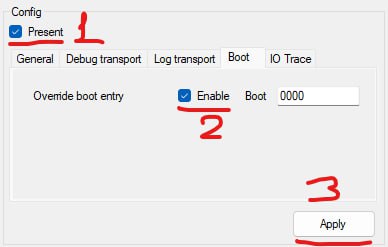
Can you try PulseConfig to edit bootx64.efi parameters?
-
This should display the list of boot entries
-
So you can learn which one is Windows
-
And then enter it in the Boot text edit to force booting to Windows
-
I'm getting a feeling that the issue is in the firmware given that single core works
-
[discord] <unrustled.jimmies> yep lemme try
-
Can you dump your ACPI tables? I would take a look. Do you know how to do that?
-
[discord] <unrustled.jimmies> [reply]: yeah it looks like intel has this tool that can do that - https://www.intel.com/content/www/us/en/download/774881/acpi-component-architecture-downloads-windows-binary-tools.htmlACPI Component Architecture Downloads (Windows* Binary Tools)
April 4, 2025. Summary of changes for version 20250404.
-
[discord] <unrustled.jimmies> [reply]: I tried this, boot entry is 0000 for windows boot manager and i see (Boot0000 Windows, Boot0001 the usb flash drive) then Load Successful on pulsedbg and then the windows boot takes over then it freezes like before.
-
Freezes? That's interesting. Hopefully we will get that hypervisor crash log someday :)
-
Thanks for trying!
-
I'll try installing the latest Windows on my ARL and see if it works for me. Sometimes Windows utilizes some instructions that need to be explicitly enabled in vmcs. Hopefully this would be the case
-
[discord] <unrustled.jimmies> [reply]: this is what acpidump outputted, https://1drv.ms/t/c/866108056c56eba9/EQ9rSQG67vdJqhu8qKBMaeMBzDHrDJ6RTfvnxIfN946KWA?e=5eXl83
As for the freezing, yeah i think pulsedbg is also behaving the same way the the test hv is where it is able to vmlaunch and i see cpuid exits etc for like 10 seconds then it just freezes, no crashing, or weird vmexits or anything like that. Im assuming that's what's happening in the efi hv as well. -
The reasons might be very different though. That's why I'm trying to get as much info as I can.
-
Thank you! Does iasl output a parsed formatted view?
-
[discord] <unrustled.jimmies> i have an idea to eliminate the windows variable completely, in pulsedbg after entering vmx if we can just loop on cpuid just to see if it freezes instead of going to the next boot.
-
[discord] <unrustled.jimmies> [reply]: yeah lemme try to find a better way to output the results
-
I've installed an old Windows 11, updating now
-
[discord] <unrustled.jimmies> [reply]: iasl generated these dsl files from the dump which looks like a more human readable forum https://1drv.ms/u/c/866108056c56eba9/Ef5_s9iZ4qxIumCuLhsXfMMB1OsRH0Qv76EhSLGdO67siw?e=zpx8HN
-
Yes, exactly what I need. Thank you!
-
Have you dumped ACPI with only one core config?
-
[discord] <unrustled.jimmies> [reply]: ah yeah this is the 1 core config
-
[discord] <unrustled.jimmies> and npu turned off as well
-
Whenever you have time, can you dump with all cores enabled?
-
NPU doesn't matter, it's a standalone device like GPU
-
You know, ACPI also seems OK
-
I'll keep digging
-
Good news man, I managed to reproduce the issue on ARL for the latest Windows 11 (24H2).
-
[discord] <unrustled.jimmies> thats good, so it was a windows 11 issue
-
[discord] <unrustled.jimmies> since thats the only variable that was changed?
-
Yeah, 22h2 worked ok
-
I'll need some time to track down the issue, but at least it's doable
-
So. Pulsedbg currently incorrectly handles CR4 register setting. 22H4 already uses CR4.LASS feature on ARL and LNL cpus. I need to rework the logic tomorrow. Possible there will be more bugs, will see.
-
As for the other hypervisors. Make sure that you enable PCONFIG, RDPID, Uwaits, rdmsrlist instruction in vmcs. Windows does use them, pretty early, and they will #UD unless enabled in VMCS. Since they are used during the early initialisation, BSOD will not be displayed, it will just hang. Just to be safe, enable all the instructions support in VMCS.
- 23 May 2025 (43 messages)
-
[discord] <unrustled.jimmies> sounds good, ill try making these changes and see if it works. thanks.
-
Joined.
-
Good news, I managed to fix the latest Windows 11 support for Arrow Lake. Can you try once more? https://pulsedbg.com/files/test/bootx64.efi
-
My problem was incorrect CR4 vmx trap handling due to a renewed CR4 layout on Arrow Lake
-
To whoever is going to fix CR4 layout, beware! There is a bug in current Intel SDM. Bit 27 in CR4 is LASS. Windows Does use it:
-
[discord] <unrustled.jimmies> [reply]: i just tried it
In all core mode, it freezes on Loading Core (been about 5 mins now).
On 1 core mode, it says Load Successful and takes me to the windows boot screen and successfully boots into windows 11. -
Good! I'll think of what could be the problem with all cores
-
[discord] <unrustled.jimmies> Does pulsesdbg set hv bit and modify name? When i tried cpuid after it booted in, it says no hv was present and name didnt change however.
-
PulseDbg is designed to leave as few traces of being virtualized as possible, so it is a complete pass through of the original hardware (less debug transports, since we can't share them with the OS)
-
[discord] <unrustled.jimmies> ok, so that's good, it's expected (i just wanted to make sure it was actually running which it should be as long as it says load successful).
-
Yeah, right. If it says successful, you're already virtualized
-
All core mode obviously suffers with AP startup failure. It's been a while since I encountered this problem.
-
And it's a "feature" of your firmware
-
Do you have your bios image file?
-
Also, can you share the ACPI tables while all cores are enabled?
-
[discord] <unrustled.jimmies> Yeah, the bios is the latest one here (released 4 days ago)
https://www.msi.com/Motherboard/PRO-Z890-P-WIFI/support
Will generate the acpi tables.PRO Z890-P WIFI | PRO Series Motherboards|Best Motherboard for AI PC|MSIPRO Z890-P WIFI Intel LGA1851 motherboard delivers simple silver design, including Wi-Fi 7, 5G LAN, Thunderbolt 4, PCIe 5.0, and M.2 Gen5. Designed for AI-PCs and EZ DIY, it’s the top Z890 ATX motherboard for Intel Core Ultra processors.
-
Thanks!
-

-
[discord] <unrustled.jimmies> [reply]: here is the acpi dump dsl files - https://1drv.ms/u/c/866108056c56eba9/EXNntXp5v2pJnyBOvmDJPN4BY1rBNM_xCU-laqVIIONZww?e=1v1EYN
-
I have to admit I have no idea why mutlicore config does not work. Everything seems to be normal both in the ACPI and in the Firmware CpuDxe.efi
-
[discord] <unrustled.jimmies> one thing i can try is to see is if the issue repros when i start an hv after windows starts.
-
Which HV?
-
[discord] <unrustled.jimmies> i can try hyperdbg or my test one. (ill have to make the changes you mentioned above however to it)
-
Cool! Hope it works!
-
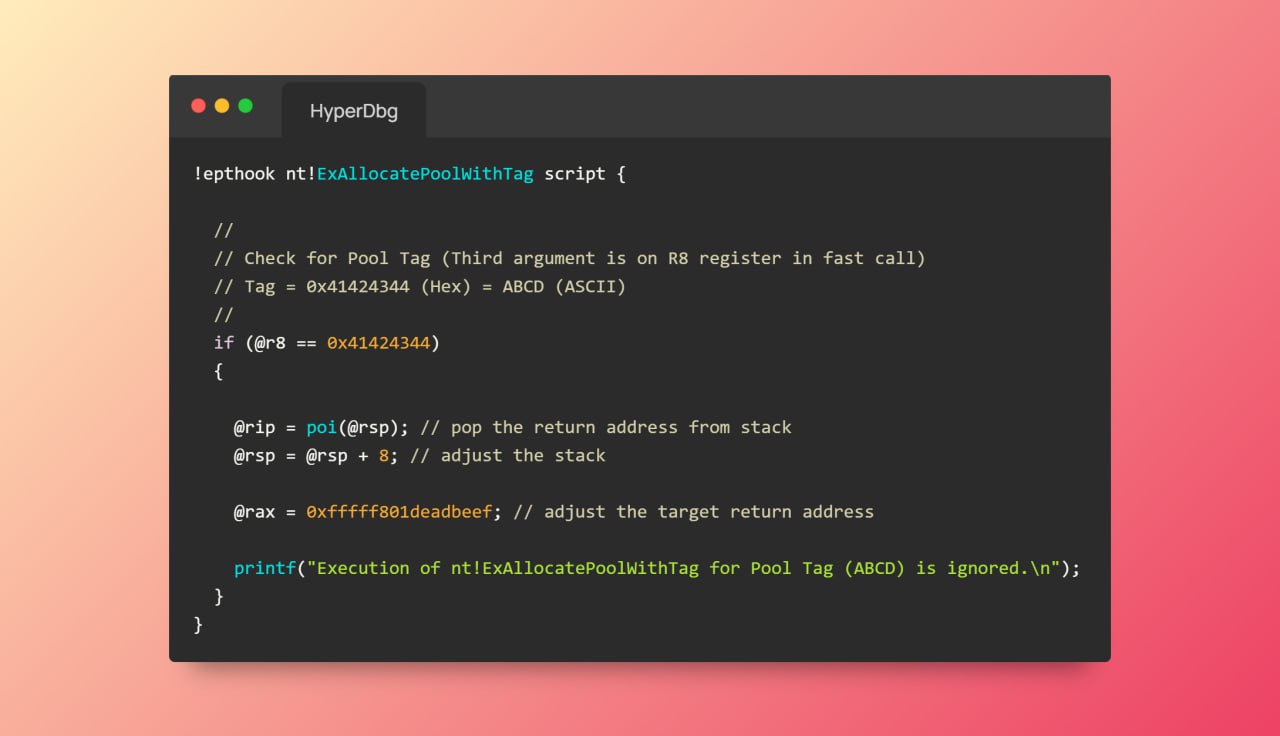
No, you can put EPT hooks with scripts.
E.g., you can log the execution of the target function:
!epthook nt!NtCreateFile script {
printf("NtCreateFile is called in the kernel, rcx: %llx\n", @rcx);
} -
I just have a random (off-topic) question, @honorary_bot. Do you know how we can find the ACPI operation range? I'm not sure if my understanding of ACPI tables is correct, but from what I understand, after the OS boots, the operating system can call some ACPI functions (whose definitions are available in the ACPI tables in AML format).
My question is: how are these functions called? And secondly, who is the handler in this case? Do we have any special memory range that is called ACPI operation range? Does calling ACPI functions trigger an SMI that's handled by the SMM handler, or am I completely misunderstanding this? -
Sure!
So as per spec there is a dedicated memory region for ACPI tables. Firmware builds those on boot. The first step is to find a root of all tables - RSDP. When using UEFI, you can get the address of it by checking out SystemTable->ConfigurationTable[iDesc].VendorGuid for being a GUID of ACPI 2.0 or 1.0, and then returning the actual address from SystemTable->ConfigurationTable[iDesc].VendorTable field.
If not found, you can get the EFI memory map and scan EfiACPIMemoryNVS and EfiACPIReclaimMemory memory types looking for the magic value of "RSD PTR " - that would be the RSDP table.
For legacy support (CSM or BIOS) RSDP is duplicated in EBDA - Extended BIOS Data Area (0xE0000-0xFFFFF). You also have to scan it for the magic value.
From there you will the pointers to all of the remaining tables. You can get multiprocessor info there, PCI ECAM address and a lot more.
One of the tables is DSDT - it has ACPI Source Language (ASL) code for platform devices. It's a cool way of skipping the need for platform drivers while being cross platform. In reality it sucks, it is a fucking hell. And those are not just my words, but word of a friend from Microsoft who used to maintain OSPM - OS Interpreter for ACPI.
So answering the question - OSPM (OS Power Management) is an operating system component that interprets ASL code from DSDT. For example on Windows acpi.sys is responsible for that. Checked builds of Windows had a special extended acpi.sys with a built in debugger for asl code. You can find a lot of references to it in WinDbg help file btw.
It does not operate on a specific range. In fact, the OS copies ACPI tables from firmware memory regions and caches them somewhere else, like registry on Windows. Execution runtime stays in the driver.
SMM is orthogonal. It does not directly imply ACPI. It is on it's own. But it's true that some devices can trigger SMIs directly. That would be the only thing connecting SMM and ACPI. -
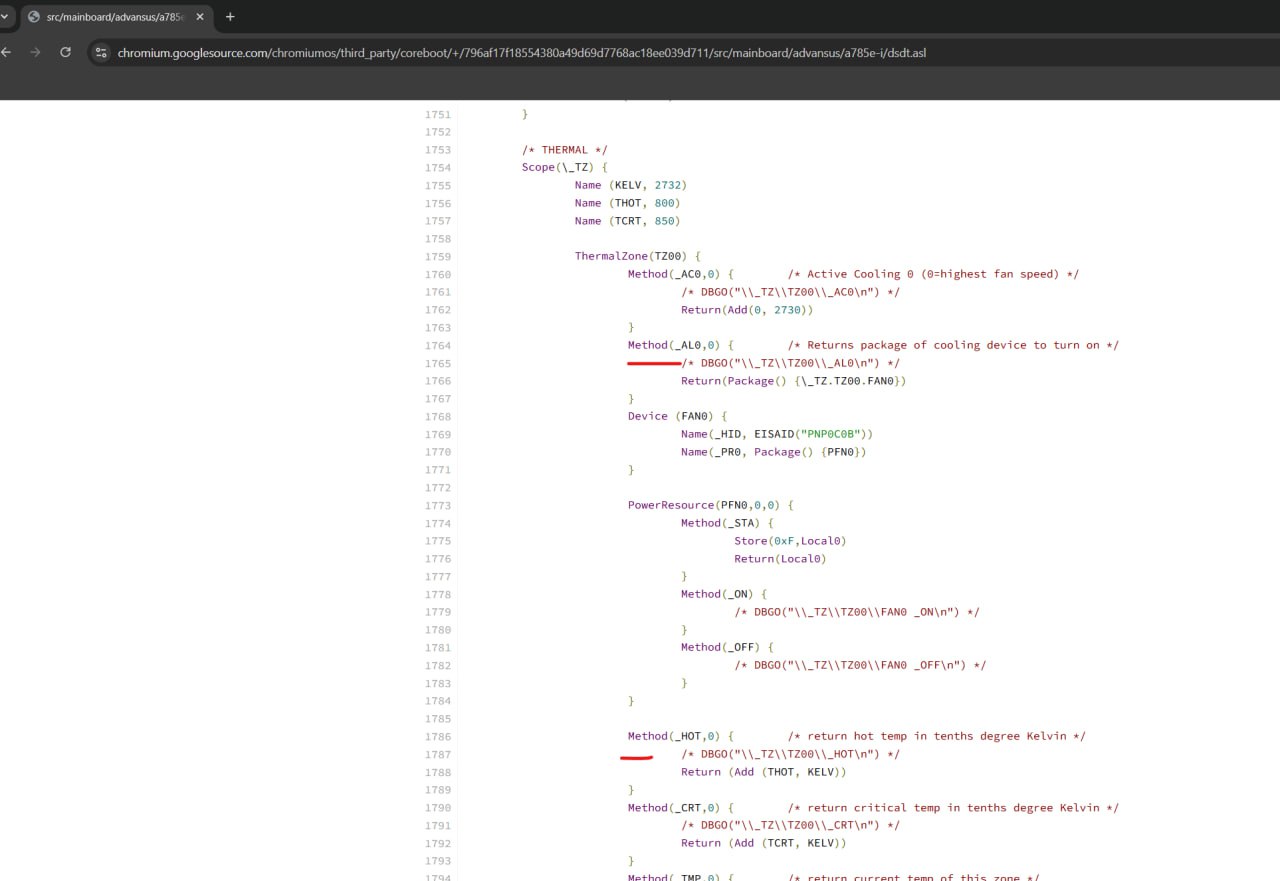
Thanks a lot for explaining this. Whenever I dump DSDT and use iasl to convert it from AML to ASL format, I'll see something like this:
https://chromium.googlesource.com/chromiumos/third_party/coreboot/+/796af17f18554380a49d69d7768ac18ee039d711/src/mainboard/advansus/a785e-i/dsdt.asl
As you can see, here is the definition of some functions that are described in ASL format. The question is, can I execute these functions? Or in other words, does Windows (acpi.sys) execute these functions? -
Yes, Windows executes this functions. There are certain power events that trigger execution of ASL code via ASL interpreter. If you want to execute them, you will have to write your own interpreter. But I would discourage you from doing that. ASL syntax is messy and DSDT is often malformed, so you need to keep workarounds for different OEMs.
-
I’m also not even sure why would you need to execute those
-
Those are purely device drivers
-
Platform devices, not even PCI necessarily
-
I just asked out of curiosity. At first, I thought that the functions in the DSDT were merely definitions of hardware functions that are executed within certain ACPI operation regions. From your explanation, I conclude that the DSDT defines the function itself, so there is no ACPI operation region or special hardware region required for that. The DSDT itself contains all the data for a function, let’s say it’s like a compiled binary where all the assembly instructions are included within the binary (the DSDT) itself, and the OS doesn’t need to know anything about any "magical" regions.
-
I asked because I had previously spoken with one of the Linux kernel ACPI maintainers, and he told me that ACPI uses operation regions. So, I assumed that what we see in the DSDT is just the definition of a function. But as you described, the body of the function and everything it needs for execution is also included in the DSDT itself.
-
So, in case if Windows (or a vendor device driver) wants to change something (let say, the keyboard background light), it needs to execute one of these ACPI functions to perform the operation (e.g., change the keyboard background color on a laptop).
-
Yeah, operation regions are ACPI terms. You have a special definition that basically describes the location of device resources and data. For example the operational region for a PCI device could be its BAR
-
Hehe, most of the time it is handled in embedded controllers, not ACPI
-
Oh, I have a good example of ACPI use
-
4. Serial port issues
Hypervisor-based debugger. Contribute to honorarybot/PulseDbg development by creating an account on GitHub.
-
There is a description of methods to disable or enabled serial ports on haswell machine
-
Serial ports live in the LPC controller on that platform. It is not a PCI device. It is managed only through IO space (io read and write). You can actually find a datasheet for haswell that will say that serial ports are linked to LPC controller and show you the port numbers that are responsible for powering them on and off.
-
So instead of writing a driver for every platform you can just use an ACPI method which basically interpreted into the same thing - in out instructions for a certain port.
-
Oh, Great. I think I do understand it now.
Thank you very much for your explanation. 🙏 - 24 May 2025 (9 messages)
-
[discord] <unrustled.jimmies> [reply]: Posting from a fully hypervised win11 h2 arl machine 🙂
-
[discord] <unrustled.jimmies> thanks for all the help bro
-
[discord] <unrustled.jimmies> I still need to add the proper CR4.LASS support you mentioned (and figure out why the EFI HV isn't working however)
-
 🧙♂️ Did you know you can easily hook, patch, or change arguments to functions both in user mode and kernel mode by using #HyperDbg?
🧙♂️ Did you know you can easily hook, patch, or change arguments to functions both in user mode and kernel mode by using #HyperDbg?
Here’s a quick example 👇 -
Joined.
-
Good job! You’re welcome!
-
[discord] <subgraphisomorphism> Wagwan
-
[discord] <unrustled.jimmies> [reply]: Hey Stranger.
-
[discord] <subgraphisomorphism> 👁️
- 25 May 2025 (1 messages)
-
HyperDbg v0.13.2 is out! 🎉
This version brings improvements and fixes stability issues in nested virtualization on Intel Meteor Lake processors.
Check it out:
https://github.com/HyperDbg/HyperDbg/releases/tag/v0.13.2Release v0.13.2 · HyperDbg/HyperDbgHyperDbg v0.13.2 is released! If you’re enjoying HyperDbg, don’t forget to give a star 🌟 on GitHub! Please visit Build & Install to configure the environment for running HyperDbg. Check out the...
- 26 May 2025 (52 messages)
-

-
-

-
-
-
No it's not possible. It is possible to add offset to a function, register, pseudo-register or a symbol. Like nt!ExAllocatePoolWithTag+5a5 or @rsp+142f-10*100/abcd+($pid+$tid/10).
-
what you can do is you can use the 'lm' command to find the base address of the module and then add your offset. E.g., fffff801`5fa40000+123abc
https://docs.hyperdbg.org/commands/debugging-commands/lmlm (view loaded modules) | HyperDbg DocumentationDescription of the 'lm' command in HyperDbg.
-
-
-
-
-
it prevent the need to change the script accross reboot
-
-
Do you mean a pull request for having the base address of the modules (e.g., NT)?
-
-
Yeah sure. Go on and create PR.
-
-
Is it a HyperDbg code?
-
-
Do we already have this? or is it your code?
-
🤔
-
-
-
Great. What about adding it as function instead of pseudo-register?
-
Why? 🤔
-
-
-
-
I say it because it would be best if we can also have rdtscp (which I think RDTSCP do need an argument as input).
-
You probably modified the code of the script engine directly without running the Python script that generates the script engine.
-
If you want to make any modification in the script engine, please go to this directory: HyperDbg\hyperdbg\script-engine\python
-
There are two files here: Grammar.txt and Boolean_Expression_Grammar.txt
-
Add your new pseudo-register or new function to them and then run the generator.py script.
-
This will create the headers, constants and the grammar files for you.
-
And after that, just implement the function.
-
-
-
Yes, that's the reason why it failed.
-
Adding a new function or pseudo-register for the first time is a bit tricky. So, feel free to ask any question or problem that you encounter adding it.
-
-
-
The script engine parser is running in the user-mode.
-
But the scripts (IRs) are evaluation and executed directly in VMX-root mode.
-
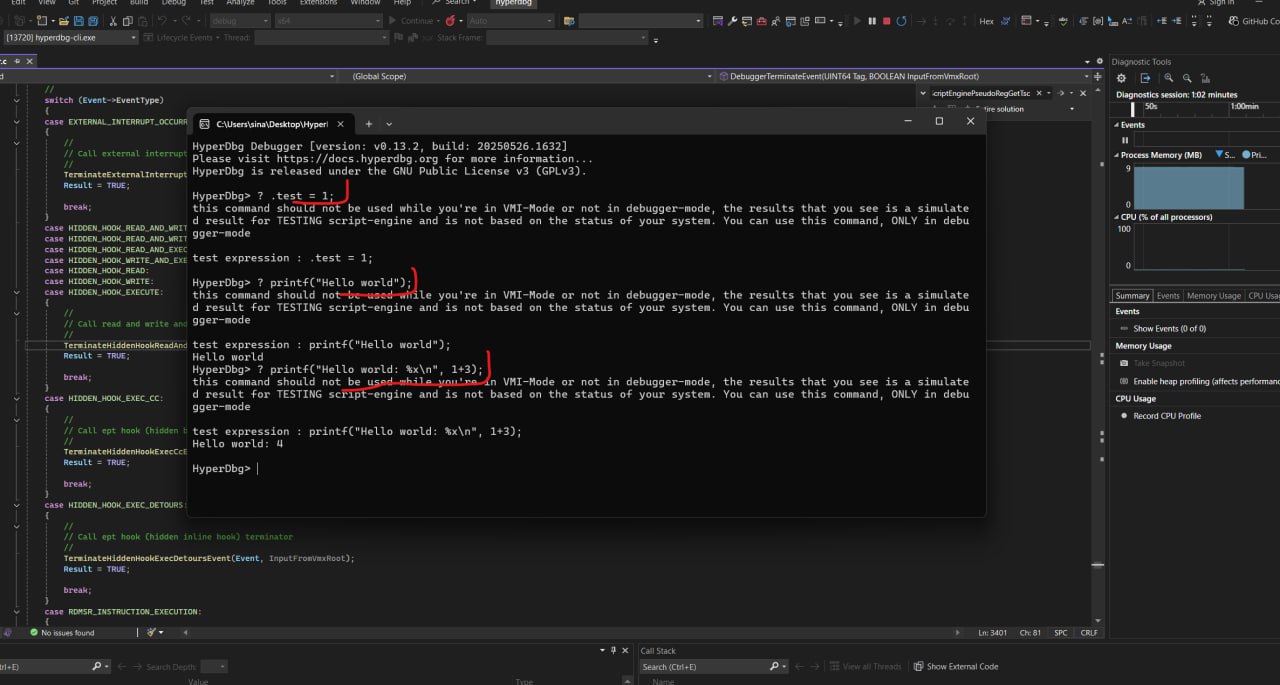
So, but they also execute in the user-mode for testing purposes. So, if you run the '?' command without connecting to a debugger in the debugger mode, it basically executes everything in the user-mode for testing purposes.
-
like this one (for testing it):
-
yeah so I'm not getting the guess tsc ?
-
-
guest tsc?
-
-
yes, in reality (whenever you connect to a debuggee in the debugger mode using the '.debug' command), you get the TSC of the target executing core (in the guest).
-
No, right now we won't restore the tsc.
-
- 27 May 2025 (8 messages)
-
[discord] <ohault> Does it possible to browse full physical memory of the guest VM using HyberDbg GUI?
-
Hey,
You can dump the virtual and physical memory using the '.dump' and '!dump' commands. It shouldn't be a problem to dump the memory (the actual RAM addresses, not MMIO/device ranges).
Virtual:
https://docs.hyperdbg.org/commands/meta-commands/.dump
Physical:
https://docs.hyperdbg.org/commands/extension-commands/dump.dump (save the virtual memory into a file) | HyperDbg DocumentationDescription of the '.dump' command in HyperDbg.
-
HyperDbg accesses the entire memory if you specify a range, so if for example you access a PCIe BAR or a PCIe ECAM address, it generates TLP packets inside CPU, so in general just make sure to specify an actual RAM range for it to avoid touching memory ranges of devices.
-
Just to follow up on this. There are also protected RAM ranges. Best case they will return all FFFFFFFF dwords and igonre write. Worst case - they will trigger #MC - machine check exceptions. Examples would be GSM and DSM (Graphics stolen memory and Data stolen memory ranges).
With MMIOs it might be a third option - the whole platform may just hang. Sometimes power wells for respective MMIOs are disable, so there's no power on the answering side. CPU will issue those memory accesses synchronously (since #UC memory) and wait for the return value indefinitely. -
Oh, it looks like you also answered one of my questions too. I had noticed that certain memory ranges trigger a #MC (Machine Check), and I initially suspected it might be related to the caching flags in the Page Table Entries (PTE) when we read it through HyperDbg. Thanks for your explanation, it clarified a lot, and now I've got a whole new set of new questions. 🤔🧐
1. For the "protected ranges", are you referring only to SMRAM, where we typically see values like FF FF FF FF? or are there other memory regions that are considered protected besides SMRAM?
2. Also, what's inside the GSM and DSM (Graphics Stolen Memory and Data Stolen Memory) regions? Why are these ranges protected? Is there any way to read from them? I'm considering creating exceptions for specific physical memory ranges, such as GSM and DSM; so HyperDbg can avoid triggering a #MC and possibly read from them safely.
3. You also mentioned #UC (Uncacheable) memory. I've seen WinDbg suggest specifying [uc] when it fails to read certain memory regions, but I wasn't entirely sure why. Initially, I assumed it was because reads/writes might be served from the cache, and marking memory as [uc] would force direct access to the device itself, bypassing the cache. But based on your explanation, that assumption is wrong? Could you clarify this point a bit more? -
Sure man!
Misconfigured EPT may also result in #MC. For example, PCI header space must be mapped as #UC, but your EPT entry may say it's #WB. The effective caching would be #WB then and CPU will try to access the memory that supposed to be accessed as #UC with #WB - this will trigger a #MC.
Note that MMIO space may use different types of caching, like #WC for framebuffers. So it is case by case scenario.
1. There are many many many protected ranges on Intel platform, Every stupid security feature relies on it's own "protected" region. Those regions may be protected for CPU access, for DMA access or for both. SMRAM is probably a well known protected region. But there are many. Can't tell you exact ones since I'm not sure they are documented, sorry.
2. GPU has its own memory view, but still uses system memory. That's why it uses its own page tables to map graphics addresses to physical addresses. GSM is a main memory stolen for global graphics address space page tables, it's a placeholder for GTT PTEs. DSM is a main memory stolen for graphics data - it is a legacy region. Older GPUs (approx before Broadwell) used a single memory region for graphics data - that size that you choose in BIOS settings. Modern iGPUs can use any system memory, not just DSM. It is protected for legacy reasons as well. CPU should not be accessing those memory regions directly, as instead it would use GPU MMIO to configure GTT PTEs and GMADR range for accessing graphics data - this way you would maintain cache coherency with between CPU and GPU.
I'd recommend building a system memory map to track MMIOs and protected regions, most of the info may be obtained from a root complex - device 0.0.0. But it is still platform specific.
3. For this I'd really recommend diving into Caching chapter in SDM when you have time and will. Because it is not just bypassing caches. Different types of caching create side effects when accessing memory from CPU. #UC is needed to serialize and control actual MMIO memory transactions in order for the device to function properly. For example, imagine a stinky I2C controller that is used to read a EDID from your monitor. In order to extract a EDID you must program the controller via MMIO and read the data by sequentially reading from a single 4 byte MMIO register. Imagine using #WB cache on it - you would not have control over when the memory request actually goes to the I2C controller. Also, I2C would expect a 32bit transaction on it's MMIO and not a full cache line fill when using #WB. -
Legend! Thanks a ton 🙌
-
- 28 May 2025 (1 messages)
-
[discord] <ohault> Super interesting, thank you. I have to think about it.
- 29 May 2025 (6 messages)
-
 Hi, I run the hyperdbg in the victim PC, and connect this PC by serial port, so can I debug the victim PC' kernel?
Hi, I run the hyperdbg in the victim PC, and connect this PC by serial port, so can I debug the victim PC' kernel? -
I read the doc of hyperdbg, it seems like it can debug the kernel of the victim pc, but i cannt confirm that.
-
In Debugger Mode, you can break the kernel mode and step through the kernel instructions. It needs a serial (cable or virtual device) to connect to the target machine. that is it
-
Hey 👋
Based on the discussion that we have in the group in the past, the serial connection over wire needs a verification (which we never add, because we never had a machine with physical serial port), so you can use it but if there is a physical error, HyperDbg will likely couldn't communicate with the debuggee. If you have a physical serial port and willing to spend a bit of time, you can debug it and fix the problem (then send PR on GitHub). -
I think the problem is because we don't have a resend mechanism in case if the serial connection have some incorrect bits.
-
Answering the questions that nobody asked again :) Serial connection is noisy, you would definitely need at least an error detection mechanism. Also, internal buffer size varies. This is the reason why my communication library is designed with a "pump" thread - a dedicated receiving thread that is always listening for incoming data.
- 31 May 2025 (1 messages)
-
Joined.
@hyperdbg / Public archive of HyperDbg Telegram messages.




- 02 May 2025 (3)
- 05 May 2025 (4)
- 06 May 2025 (41)
- 07 May 2025 (3)
- 08 May 2025 (6)
- 12 May 2025 (2)
- 13 May 2025 (5)
- 14 May 2025 (4)
- 17 May 2025 (64)
- 18 May 2025 (2)
- 19 May 2025 (1)
- 20 May 2025 (16)
- 21 May 2025 (13)
- 22 May 2025 (53)
- 23 May 2025 (43)
- 24 May 2025 (9)
- 25 May 2025 (1)
- 26 May 2025 (52)
- 27 May 2025 (8)
- 28 May 2025 (1)
- 29 May 2025 (6)
- 31 May 2025 (1)