- 01 June 2024 (1 messages)
-
 OK,thank you
OK,thank you - 03 June 2024 (3 messages)
-
Joined.
-
-
Joined.
- 04 June 2024 (75 messages)
-

-
 Guys,
Guys,
Has anyone previously seen any sample of setting up a TSS (Task State Segment) for a hypervisor?
https://github.com/HyperDbg/HyperDbg/blob/834b43ece965c75bd65761386384a539bd1a3973/hyperdbg/hprdbghv/code/memory/Segmentation.c#L123C5-L123C6 -
Been working on setting a separate TSS (instead of Windows TSS) for HyperDbg, but not sure if I correctly implemented it since the interrupt stack is not within the range. 🤔
-
It still perfectly works but if we're unsure about the correctness of the implementation, it probably causes weird problems in the future.
-
(05:19:52.472 - core : 0 - vmx-root? no) [+] Information (SegmentPrepareHostGdt:123) | Host Interrupt Stack, from: ffffe58189199000, to: ffffe5818919cff0
(05:19:52.472 - core : 1 - vmx-root? no) [+] Information (SegmentPrepareHostGdt:123) | Host Interrupt Stack, from: ffffe581891ab000, to: ffffe581891aeff0
(05:19:52.472 - core : 3 - vmx-root? no) [+] Information (SegmentPrepareHostGdt:123) | Host Interrupt Stack, from: ffffe581891cf000, to: ffffe581891d2ff0
(05:19:52.472 - core : 2 - vmx-root? no) [+] Information (SegmentPrepareHostGdt:123) | Host Interrupt Stack, from: ffffe581891bd000, to: ffffe581891c0ff0
(05:24:27.278 - core : 0 - vmx-root? yes) [+] Information (IdtEmulationhandleHostInterrupt:177) | Host exception, RIP=fffff804383f5a8e, RSP=ffffe58189192ed0, Vector=3
(05:24:27.333 - core : 1 - vmx-root? yes) [+] Information (IdtEmulationhandleHostInterrupt:177) | Host exception, RIP=fffff804383f5a8e, RSP=ffffe581891a4ed0, Vector=3
(05:24:27.259 - core : 2 - vmx-root? yes) [+] Information (IdtEmulationhandleHostInterrupt:177) | Host exception, RIP=fffff804383f5a8e, RSP=ffffe581891b6ed0, Vector=3
(05:24:27.278 - core : 3 - vmx-root? yes) [+] Information (IdtEmulationhandleHostInterrupt:177) | Host exception, RIP=fffff804383f5a8e, RSP=ffffe581891c8ed0, Vector=3 -
-
@honorary_bot do have any idea about this?
-
The problem here is that the exception stack is not within the core's allocated range.
-
 I don’t remember from top of my head, gonna have to recheck in the evening. So you’ve set up tss stack pointers, but the exception stack is switched to something different in exception?
I don’t remember from top of my head, gonna have to recheck in the evening. So you’ve set up tss stack pointers, but the exception stack is switched to something different in exception? -
Yes, exactly
-
As stack grows downward, probably I should put the latest (aligned byte address) of the stack. But it seems that Intel didn't mention it. So, not sure whether I should put the base address or the end of the stack.
-
It’s likely just a misconfiguration, but I’ll check how I do that
-
Do you index cores by apic id?
-
Still, the base address as the stack doesn't make sense since the processor doesn't have any idea about the end of the stack.
-
By KeGetCurrentProcessorNumberEx, not sure if it's based on APIC ID or not.
-
Surely it's from prcb, so i'd need to check prcb init code, which is more than 2 minutes :\
-
But both VMCS HOST IDT exception handler and the code that I wrote use the same core number, so does it make any difference? 🤔
-
You're right, just wanted to make sure
-
Wait a sec, you were asking about TSS first, but then you're talking about IDT and exceptions
-
Also, which exception are you testing?
-
Vector number 3 (#BP)
-
A breakpoint within VMX-root mode.
-
PULSE_STATUS VmUtilAllocateStack(uint64_t aStackSize, uint64_t *aStackBase)
{
if (aStackBase == NULL)
return PULSE_STATUS_INVALID_PARAMETER;
if ((aStackSize < PAGE_4K_SIZE) || (aStackSize > g_vmm.LoaderParams.CoreRegionSize))
return PULSE_STATUS_INVALID_PARAMETER;
*aStackBase = PoolAllocPages(aStackSize / PAGE_4K_SIZE);
if (*aStackBase == NULL)
return PULSE_STATUS_INSUFFICIENT_RESOURCES;
return PULSE_STATUS_SUCCESS;
}
PULSE_STATUS VmUtilAllocateInitStack(uint64_t aStackSize, uint64_t *aStackBase)
{
PULSE_STATUS status = PULSE_STATUS_SUCCESS;
status = VmUtilAllocateStack(aStackSize, aStackBase);
if (status != PULSE_STATUS_SUCCESS)
return status;
*aStackBase = *aStackBase + (aStackSize - 8);
return PULSE_STATUS_SUCCESS;
} -
If it helps
-
pTss->Rsp0 = pHostCpu->Stack;
status = VmUtilAllocateInitStack(0x1000, &(pTss->IST1));
if (status != PULSE_STATUS_SUCCESS)
return status;
status = VmUtilAllocateInitStack(0x1000, &(pTss->IST2));
if (status != PULSE_STATUS_SUCCESS)
return status;
status = VmUtilAllocateInitStack(0x1000, &(pTss->IST3));
if (status != PULSE_STATUS_SUCCESS)
return status; -
Can you also share what you configured for HOST_GDT_BASE and how you configured other fields of pTss?
-
Is it a VMCS field? Sorry, I did that in 2015, so I don't really remember :)
-
Just wanna re-check it with my configuration since I did the exact same config but it seems the stack RSP of exception is not within range for some other reasons.
-
No, just the value of HOST_GDTR_BASE
-
I only configured IoMapBaseAddress to 100 (which is incorrect btw, but it doesn't matter in my case) and pTss->Rsp0 = pHostCpu->Stack; which is also allocated by function above.
-
Since we previously use Windows GDT and IDT as Host GDT and IDT, right now I changed the implementation to configure our own GDT, IDT.
-
Yeah, but what structy is it in?
-
or is it gdtr reg?
-
GDTR reg (for host) needs to have some entries (and the TSS should be here).
-
The TSS itself has other bits (in its entry on GDT, like LowSegmentLimit etc. ) I'm not sure if I correctly configured that.
-
Since basically I did the same in HyperDbg but still the stack is not within the expected range, I think it might be an issue with the actual TSS entry configuration in GDT.
-
Let me step back a bit. It is still not clear to me what you're trying to achieve.
-
Sp you set up a dedicated gdtr for vmx root mode, right?
-
Yes
-
Then the OS runs in a vmx non root (guest) mode, right?
-
Yes
-
So, you want to trap a breakpoint, but does it occur in vmx root on vmx non root mode?
-
And I wanted to build a dedicated gdt for Host.
-
It occurs in vmx root mode.
-
You have also filled vmcs like this?
if (__vmx_vmwrite(VMCE_HOST_GDTR_BASE, g_vmm.pCpu[CpuSlot].HostCpu.DescTables) != 0)
return PULSE_STATUS_VMWRITE_FAILED;
if (__vmx_vmwrite(VMCE_HOST_IDTR_BASE, g_vmm.pCpu[CpuSlot].HostCpu.InterruptDesc) != 0)
return PULSE_STATUS_VMWRITE_FAILED;
if (__vmx_vmwrite(VMCE_HOST_TSS_BASE, g_vmm.pCpu[CpuSlot].HostCpu.Tss) != 0)
return PULSE_STATUS_VMWRITE_FAILED; -
Since we configured TSS stack for IST3, the breakpoint should be handled with host ID (the one dedicated to HyperDbg) but the rsp of the arrived breakpoint is not within the expected range.
-
Is your root mode operating in Rind0 mode?
-
Ignore the structs, the just should be some address
-
Yes exactly. And what I need is how you filled/configureed g_vmm.pCpu[CpuSlot].HostCpu.Tss and g_vmm.pCpu[CpuSlot].HostCpu.DescTable.
-
?
-
// Task entries
uint64_t tssAddr = &(pIdtEntry[256]);
PCPU_TSS_DESCRIPTOR64 pTssEntry = (PCPU_TSS_DESCRIPTOR64)(&(pGdtEntry[VMM_HOST_TASK_SEG_DESC_NUM]));
pTssEntry->P = 1;
pTssEntry->S = 0;
pTssEntry->Type = SYS_SEG_TYPE_AVAIL_TSS64;
pTssEntry->LimitLow = sizeof(CPU_TSS64);
pTssEntry->LimitHigh = 0;
pTssEntry->BaseLow = tssAddr & 0xFFFF;
pTssEntry->BaseMid = (tssAddr >> 16) & 0xFF;
pTssEntry->BaseHigh = (tssAddr >> 24) & 0xFF;
pTssEntry->BaseAddrHigh64 = (tssAddr >> 32) & 0xFFFFFFFF;
pTssEntry->AVL = 0;
pTssEntry->G = 0;
pTssEntry->DPL = 0;
pTssEntry->DB = 0;
pTssEntry->L = 0;
// TSS
pHostCpu->Tss = tssAddr;
PCPU_TSS64 pTss = (PCPU_TSS64)(tssAddr);
pTss->IoMapBaseAddress = 100; // 104 ?
pTss->Rsp0 = pHostCpu->Stack;
status = VmUtilAllocateInitStack(0x1000, &(pTss->IST1));
if (status != PULSE_STATUS_SUCCESS)
return status;
status = VmUtilAllocateInitStack(0x1000, &(pTss->IST2));
if (status != PULSE_STATUS_SUCCESS)
return status;
status = VmUtilAllocateInitStack(0x1000, &(pTss->IST3));
if (status != PULSE_STATUS_SUCCESS)
return status; -
Rind0 mode?
-
ring 0
-
Yes, but curious to know, could run in any different modes? 🤨
-
Well that's why it's working like that
-
You have no ring transition
-
You're already in ring 0
-
So no stack switch for you
-
Of course you could run VMX root ring 3
-
But it's a breakpoint (so shouldn't it use Tss.IST3?)
-
Didn't knew that 😳
-
Like a user-mode application running in VMX root mode?
-
From top of my head - only NMIs, double faults and smth else would have a separate stack
-
Don't really remember about int3, but it makes sense not to switch the stack for it
-
You can create an operating system running in VMX root, right? It would have both kernel and user mode
-
Ah, if it's the way you say, then that's why the stack is not within the range.
-
yes, it just uses your current rsp
-
So, basically the implementation is correct.
-
So stack switch is for NMI, DebugOrTrap (int1 though, not 3), double fault, machine check
-
It makes sense to swap stack for int1, because you can trap task switcch with debug registers
-
but int3 is just a code breakpoint
-
Makes sense.
-
Anyway, thank you for always being helpful. You saved me a lot of time for this.
-
No problem!
-
- 05 June 2024 (2 messages)
-
Hello everyone,
I've made a somehow big update in the HyperDbg. Now, it utilizes a dedicated HOST IDT and HOST GDT, different than the Windows IDT/GDT. This update will address a specific category of bypasses for HyperDbg, although there are still many bypasses to address. This change influences the handling of interrupts, especially NMIs for halting cores in VMX root-mode. lt may introduce instability issues in various systems, potentially leading to crashes. If you're using HyperDbg, please switch to the 'dev' branch and re-build and test it to help us identify any problems. Currently, it works well on my 12th Gen machine, but I'm uncertain if it's universally stable. If you encounter any crashes or BSODs, please notify me before the release of v0.9 (the next version). The best way to test it is using events (EPT hooks) with a high rate of execution (e.g., using !epthook on nt!ExAllocatePoolWithTag and meanwhile pause the debuggee).
The 'dev' branch:
https://github.com/HyperDbg/HyperDbg/tree/dev
GitHub built artifact for those who can't build:
https://github.com/HyperDbg/HyperDbg/actions/runs/9384856535GitHub - HyperDbg/HyperDbg at devState-of-the-art native debugging tool. Contribute to HyperDbg/HyperDbg development by creating an account on GitHub.
-
None
- 06 June 2024 (3 messages)
-
Joined.
-
One more thing to mention, if you guys encounter "invalid address error", this new instruction is for fixing it:
https://docs.hyperdbg.org/tips-and-tricks/considerations/accessing-invalid-addressAccessing Invalid Address | HyperDbg DocumentationConsiderations for accessing memory in different modes
-
The primary difference is that previously (before v0.9), the '.pagein' command doesn't guarantee locking all the cores and immediately after the '.pagein' command, you couldn't apply any events (e.g., !epthook or !monitor) but since HyperDbg uses a dedicated Host IDT at its newest version, it is guaranteed to lock all the cores after running the '.pagein' command. Hence, you shouldn't have any problem applying events after forcing OS to bring the pages into the page-table or make them present in the current process's memory.
- 08 June 2024 (3 messages)
-
-
Hi guys!
As a new feature, starting from v0.9 HyperDbg will support monitoring EPT hooks on physical addresses (previously it only supported virtual addresses), mainly through the 'MemoryType' parameter. You can now use it from the 'dev' branch.
https://docs.hyperdbg.org/commands/extension-commands/monitor -
This is mainly useful for those who want to monitor PCIe buffers.
- 09 June 2024 (5 messages)
-
-
HyperDbg v0.9 is released! ✨
It features monitoring physical addresses for tracking read/write to PCI-e and IOMMU buffers. Plus, HyperDbg now uses a dedicated Host IDT/GDT.
🔗 Check it out: https://github.com/HyperDbg/HyperDbg/releases/tag/v0.9.0
📖 Read more:
https://docs.hyperdbg.org/commands/extension-commands/monitor
# Added
- The !monitor command now physical address hooking
- hwdbg is merged to HyperDbg codebase
- strncmp(Str1, Str2, Num), and wcsncmp(WStr1, WStr2, Num) functions in script engine
# Changed
- Using a separate HOST IDT in VMCS (not OS IDT)
- Using a dedicated HOST GDT and TSS Stack
- Checking for race-condition of not locked cores before applying instant-events and switching cores
- The error message for invalid address is changed (more information)
- Fix the problem of not locking all cores after running the '.pagein' commandRelease v0.9.0 · HyperDbg/HyperDbgHyperDbg v0.9.0 is released! If you’re enjoying HyperDbg, don’t forget to give a star 🌟 on GitHub! Please visit Build & Install to configure the environment for running HyperDbg. Check out the ...
-
 Joined.
Joined. -

-
Joined.
- 10 June 2024 (2 messages)
-
Joined.
-
- 12 June 2024 (1 messages)
-
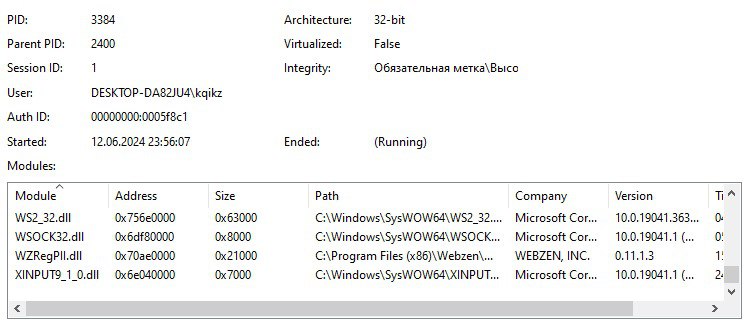
Hi, maybe i missed something in manual - looks like hyperdbg is showing only 64 kernel modules, how better to debug SysWOW64 apps ?
- 13 June 2024 (98 messages)
-
HyperDbg supports debugging 32-bits apps. You just need to use special commands (e.g., 'u32' instead of 'u' for disassembling codes), but in case if you use the wrong command ('u32' on a 64-bit app or 'u' on a 32-bit app, it will show a message and notify you. Other than everything is similar to debugging a 64 bit app.
-
About kernel modules, is there any 32 bit driver on a 64 bit machine? If I remember correctly that's not possible in Windows. 🤔
-
-
-
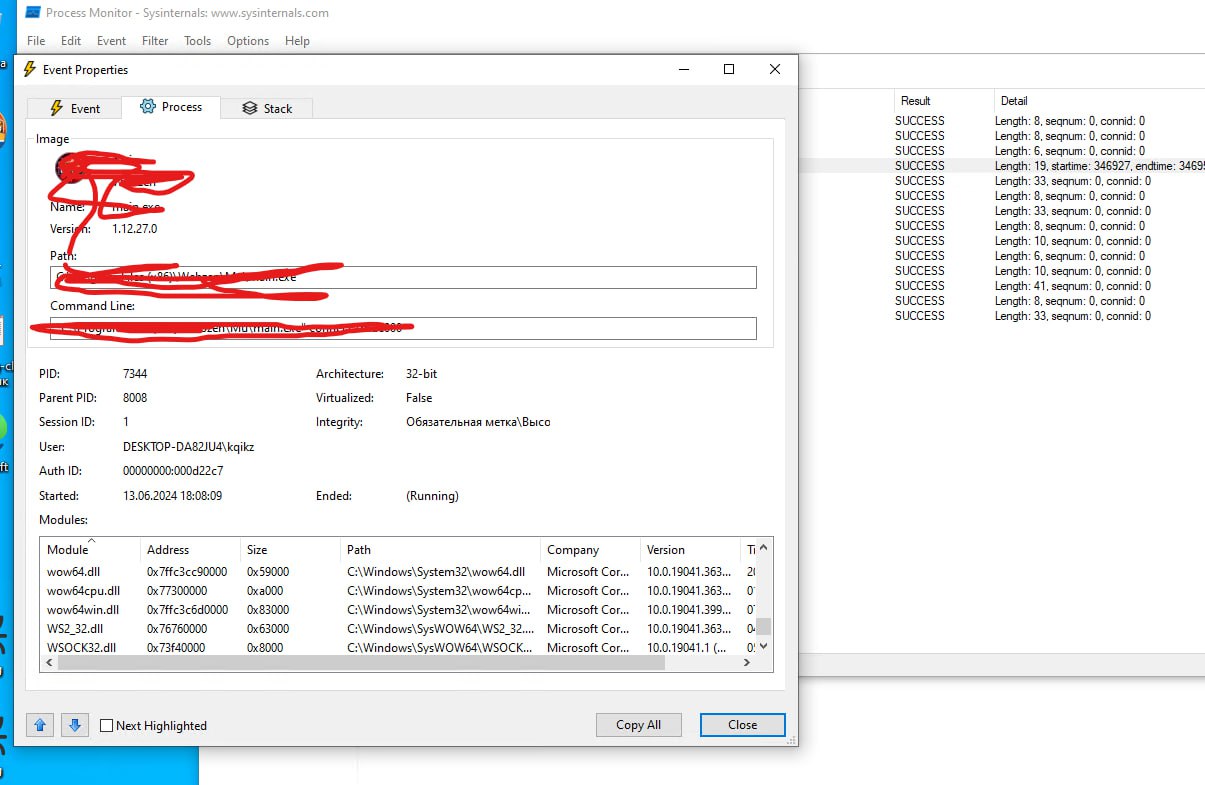
here is screen from process monitor, i dont see those modules neither in user or kernel mode
-
@HughEverett hey man! I don’t know why I recalled it now, but remember you were asking about vmx root ring3 mode? The obvious example is when you’re running VMware workstation on windows. When you launch a VM, your Windows becomes a vmx root, right? That basically means it keeps working in vmx root, while still having kernel and user modes ;)
-
Not sure if I understand it correctly, what is this screen?
-
HyperDbg doesn't support 32 bit operating systems but it fully supports 32 bit applications in 64 bit operating systems.
-
Oh, that's interesting. Initially I thought that they virtualize the entire system and handle these things from Host Kernel-mode, but this kind of design (using Host User-mode) is really cool. 👌
-
here is full screen. guest is w10 x64. process monitor shows all loaded modules by particular process (like WSOCK32.dll in which im interested), but i cant find any reference to it in hpyerdbg
-
Did you try the 'lm' command in HyperDbg? Isn't it what you need?
https://docs.hyperdbg.org/commands/debugging-commands/lmlm (view loaded modules) | HyperDbg DocumentationDescription of the 'lm' command in HyperDbg.
-
1: kHyperDbg> lm m sock
user mode
start entrypoint path
==============================================================================
kernel mode
start size name path
fffff803`35ba0000 18000 vsock.sys \SystemRoot\system32\DRIVERS\vsock.sys
fffff804`15471282 0F 01 C1 vmcall -
thats all
-
The 'lm' command has a 'pid' argument, did you try that?
By default if you're in the context of hyperdbg-cli.exe then it shows the modules of the hyperdbg process. You can check it by using the '.process' command. -
HyperDbg> lm um m kernel pid 1240
user mode
start entrypoint path
00007ffd88860000 00007ffd888770d0 C:\Windows\System32\KERNEL32.DLL
00007ffd865f0000 00007ffd865f92c0 C:\Windows\System32\KERNELBASE.dll -
0: kHyperDbg> g
debuggee is running...
fffff804`15471282 0F 01 C1 vmcall
1: kHyperDbg> .process pid 1cb0
press 'g' to continue the debuggee, if the pid or the process object address is valid then the debuggee will be automatically paused when it attached to the target process
1: kHyperDbg> g
debuggee is running...
switched to the specified process
00000000`759d8e34 89 44 8F F0 mov dword ptr ds:[edi+ecx*4-0x10], eax
0: kHyperDbg> lm m sock
user mode
start entrypoint path
==============================================================================
kernel mode
start size name path
fffff803`35ba0000 18000 vsock.sys \SystemRoot\system32\DRIVERS\vsock.sys
fffff804`15471282 0F 01 C1 vmcall -
Use it like: lm m sock pid 1cb0
-
1: kHyperDbg> lm m sock pid 1cb0
err, error not found (0)
==============================================================================
kernel mode
start size name path
fffff803`35ba0000 18000 vsock.sys \SystemRoot\system32\DRIVERS\vsock.sys
fffff804`15471282 0F 01 C1 vmcall
same.. i definetly know, that process is trying to hide itself, thats why user mode might be empty.. -
You mean the process uses some kind of anti-debugging techniques?
-
yes
-
it fails instantly when i attach any other debugger
-
i managed to intercept some kernel calls like AfdTLStartBufferedVcSend, but i dont see trace, that leads to process executable
-
HyperDbg simply reads the user mode modules list from PEB but it's highly probable that due to an anti-debugging technique the process hides it's PEB.
-
WSOCK32.dll is user module, so you can simply read it's address from any other processes.
-
hm.. good idea actually. i wonder why process monitor sees its modules..
-
The addresses remain constant in Windows (before you restart), which is in contrast to Linux (which creates new ASLR addresses each time you run a new process).
-
Yep, that's interesting. I don't have any idea where they gather their user-mode modules list. 🤔
-
yea.. will try to compile simple send as 32 bit app and see
-
thanx
-
Also, if you have problem loading symbol files for your target process, try to run a similar 32-bit process (that loads WSOCK32.dll) and then HyperDbg even if you switch to other processes, still uses the old symbol table. Which will be useful for your case.
-
perfect! with 32bit simple send
0: kHyperDbg> lm m sock pid 0x814
user mode
start entrypoint path
00000000742b0000 00000000742ba0a0 c:\Windows\SysWOW64\mswsock.dll
==============================================================================
kernel mode
start size name path
fffff803`35ba0000 18000 vsock.sys \SystemRoot\system32\DRIVERS\vsock.sys
fffff804`15471282 0F 01 C1 vmcall
1: kHyperDbg> g
debuggee is running... -
not wsock, but looks like im somwhere near
-
0: kHyperDbg> x mswsock!*
damn... will need to inspect this dll -
Does it work? Is your process corrupting symbol hashes?
-
for some reason, hyperdbg isnt trying to load symbols for that dll.. its from simple send
-
ida downloads symbols just fine
-
hmm
1: kHyperDbg> .process pid 0814
press 'g' to continue the debuggee, if the pid or the process object address is valid then the debuggee will be automatically paused when it attached to the target process
1: kHyperDbg> g
debuggee is running...
switched to the specified process
ntkrnlmp!ExpQueueWorkItem+0x37:
fffff803`30cc8617 8B 05 43 40 A3 00 mov eax, dword ptr ds:[<ntkrnlmp!KiIrqlFlags (fffff803`316fc660)>]
1: kHyperDbg> bp 00007ffc`3bc92320
err, edit memory request has invalid address based on current process layout, the address might be valid but not present in the ram (c000000c)
1: kHyperDbg> x ws2_32!send
00007ffc`3bc92320 ws2_32!send
1: kHyperDbg>
0814 is simple send... -
why it cant set brakepoint there ?
-
1: kHyperDbg> bp 00007ffc`3bc92320 pid 0814
err, edit memory request has invalid address based on current process layout, the address might be valid but not present in the ram (c000000c)
this also fails -
Are you sure the address is valid?
-
x ws2_32!send
00007ffc`3bc92320 ws2_32!send -
doesn`t this guarantee that address is valid ?
-
Did you check this? https://docs.hyperdbg.org/tips-and-tricks/considerations/accessing-invalid-addressAccessing Invalid Address | HyperDbg Documentation
Considerations for accessing memory in different modes
-
nope :) will try
-
yess.. now it set-up that breakepoint
-
thanks again :)
-
1: kHyperDbg> x mswsock!WSPSend
00000000`746be0a0 mswsock!WSPSend
1: kHyperDbg> g
debuggee is running...
fffff807`ef9d1282 0F 01 C1 vmcall
1: kHyperDbg> !epthook mswsock!WSPSend script {
> printf("mswsock WSPSend PROC %x NAME %s\n",$proc,$pname);
> }
err, invalid address (c0000005)
1: kHyperDbg> !epthook 00000000`746be0a0 script {
> printf("mswsock WSPSend PROC %x NAME %s\n",$proc,$pname);
> }
err, invalid address (c0000005)
1: kHyperDbg> .pagein mswsock!WSPSend
the page-fault is delivered to the target thread
press 'g' to continue debuggee (the current thread will execute ONLY one instruction and will be halted again)...
1: kHyperDbg> g
debuggee is running...
vm immediately restarts :( -
looks like some windows service doesnt like pagefault
-
Are you sure that you're using the latest version v0.9?
-
lemme check...
-
I'm pretty sure I changed the error message for invalid access
-
Once you run HyperDbg it shows the version + build.
-
ow.. 0.8.4
-
Could you test the same command (which restarts your computer immediately) with v0.9?
-
sec..
-
1: kHyperDbg> x mswsock!WSPSend
00000000`74fae0a0 mswsock!WSPSend
1: kHyperDbg> .pagein mswsock!WSPSend
the page-fault is delivered to the target thread
press 'g' to continue debuggee (the current thread will execute ONLY one instruction and will be halted again)...
1: kHyperDbg> g
debuggee is running...
immediate restart -
both server and client is 0.9
-
Crashed?
-
yes. just after last g
-
No BSOD? Just restart?
-
yes, vmware immediatly starts system again
-
🤔
-
Could you change the flag of the '.pagein'?
Use it like:
.pagein u Address
And if it crashed again:
.pagein pf Address
https://docs.hyperdbg.org/commands/meta-commands/.pagein.pagein (bring the page into the RAM) | HyperDbg DocumentationDescription of the '.pagein' command in HyperDbg.
-
I'm gonna see whether it's a #PF misconfiguration or a VMware error. Because generally, we're just injecting page-fault, it shouldn't crash the vCpu. 🤔
-
And one more thing, are you sure that you're using the '.pagein' in a valid process?
-
I mean you might accidentally inject the page-fault while HyperDbg is in its own process (hyperdbg-cli.exe), in this case, a crash is inevitable.
-
Since the address is not valid/assigned in hyperdbg-cli.exe's CR3.
-
You could check the current process by using the '.process' command.
-
understood, let me try
-
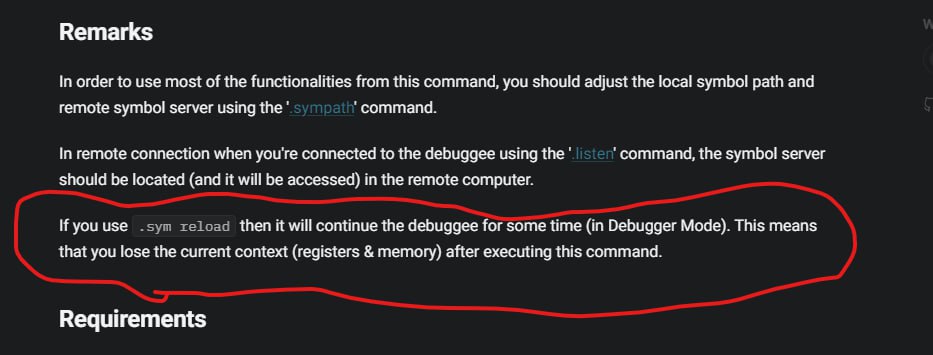
1: kHyperDbg> .sym reload pid 0x1b60
interpreting symbols and creating symbol maps
symbol table updated successfully
1: kHyperDbg> .process pid 0x1b60
press 'g' to continue the debuggee, if the pid or the process object address is valid then the debuggee will be automatically paused when it attached to the target process
1: kHyperDbg> g
debuggee is running...
switched to the specified process
ntkrnlmp!IopResetEvent+0x2e:
fffff801`0642d7ee 48 8D 70 FD lea rsi, ds:[rax-0x03]
0: kHyperDbg> .process
process id: 1b60
process (_EPROCESS): ffffaf8f`53e7a080
process name (16-Byte): simple_send.ex
0: kHyperDbg> x mswsock!WSPSend
00000000`741de0a0 mswsock!WSPSend
0: kHyperDbg> .pagein u mswsock!WSPSend
the page-fault is delivered to the target thread
press 'g' to continue debuggee (the current thread will execute ONLY one instruction and will be halted again)...
0: kHyperDbg> g
debuggee is running...
crash -
And it also crashes without 'u' in the '.pagein'?
-
yes, let me try pf
-
I think I understand the problem. This crash happens probably because you halted the process in the kernel-mode right before switching to another process.
-
@HughEverett seems like you have a symbol engine. Do you use MS DIA?
-
1: kHyperDbg> x mswsock!WSPSend
00000000`741ce0a0 mswsock!WSPSend
1: kHyperDbg> .pagein pf mswsock!WSPSend
the page-fault is delivered to the target thread
press 'g' to continue debuggee (the current thread will execute ONLY one instruction and will be halted again)...
1: kHyperDbg> g
debuggee is running...
crash... -
You need to grab the execution in other ways (other than using .process).
-
Do you start the process using the '.start' command?
-
no
-
Could you try to start it with the '.start' command? and once HyperDbg halted your process, reaching to the entry point, use the '.pagein'.
-
Yes, HyperDbg uses DIA SDK.
-
.start (start a new process) | HyperDbg Documentation
Description of the '.start' command in HyperDbg.
-
Or if you can halt the process any other ways, like putting breakpoint somewhere or any other methods, then use the '.pagein'. I think the problem is with the state we intercept the execution using the '.process' command. 🤔
-
One option is using the '!monitor' command with 'x' attribute on the memory range of the main module of the target process. In this case, if you're main module fetches instructions, then HyperDbg halts debuggee for you.
https://docs.hyperdbg.org/commands/extension-commands/monitor!monitor (monitor read/write/execute to a range of memory) | HyperDbg DocumentationDescription of the '!monitor' command in HyperDbg.
-
i know about monitor, lets try load another function first
-
.start is not an option with real process, it might work with simple_send, but antidebugger does not allow to start process properly when i use .start, tried that
-
Are you sure? The way that we start process is not same as other debuggers.
-
i will try to reproduce a bit later, lets try with other function first
-
HyperDbg doesn't use the DEBUG flag for the CreateProcess win32 API.
-
If you couldn't fix the issue, I'll come with more options/solutions tomorrow. I'm gonna go sleep now. 😴💤
Will continue tomorrow ✋ -
sure, good night!
-
1: kHyperDbg> .process pid 2064
press 'g' to continue the debuggee, if the pid or the process object address is valid then the debuggee will be automatically paused when it attached to the target process
1: kHyperDbg> g
debuggee is running...
switched to the specified process
ntkrnlmp!ExpAcquireSpinLockExclusive+0x96:
fffff807`2f82bbb6 8B 17 mov edx, dword ptr ds:[rdi]
1: kHyperDbg> .sym reload pid 2064
interpreting symbols and creating symbol maps
symbol table updated successfully
0: kHyperDbg> x mswsock!WSPSend
00000000`74b3e0a0 mswsock!WSPSend
somwhere in instructions above, process changes to debug-cli
0: kHyperDbg> bp 00000000`74b3e0a0
err, edit memory request has invalid address based on current process layout, the address might be valid but not present in the ram (c000000c)
0: kHyperDbg> .process
process id: 22b0
process (_EPROCESS): ffffbe09`11cd6080
process name (16-Byte): hyperdbg-cli.e
0: kHyperDbg> .process pid 2064
press 'g' to continue the debuggee, if the pid or the process object address is valid then the debuggee will be automatically paused when it attached to the target process
0: kHyperDbg> g
debuggee is running...
switched to the specified process
ntkrnlmp!KiSwapThread+0x56d:
fffff807`2f838a9d 48 8B C3 mov rax, rbx
0: kHyperDbg> x mswsock!WSPSend
00000000`74b3e0a0 mswsock!WSPSend
0: kHyperDbg> bp 00000000`74b3e0a0
—here fine
0: kHyperDbg>
something like that :) -
but im not loading page
-
(and it works perfect for "real" process)
-
so.. looks like any invalid command and also "x" switches process to hyperdebug cli, thats causing problems with loading page
-
 Joined.
Joined. -
-
Good morning everyone. Have a nice day.
-

- 14 June 2024 (26 messages)
-
No, neither the 'x' command nor an invalid command switch to another process, all of them stick to the current running process without continuing debuggee.
-
Didn't get it, does it fix the problem? 🤨
-
Joined.
-
Yes, problem fixed. Probably it is due to sym reload, as process runs for some time and then stops again, but in debugcli process.
-
Also I don't know if this is expected behavior - symbols for user mode 32 bit process, does not load automatically, I need to call sym reload each time, to get them appear in x
-
.sym reload will continue the debuggee the debuggee but .sym load doesn't continue it.
https://docs.hyperdbg.org/commands/meta-commands/.sym -
You just need to run '.sym reload' one time and after that the symbol table remains constant until next '.sym reload'.
-
Yes, this is expected behavior since by default once you load HyperDbg it transfers only 64-bit symbols.
-
ah.. but seems .load still doesnt load 32b symbols, but anyway, im quite fine with reload :)
-
.sym load load symbol files based on the current symbol table that is available in the debugger (host) not debuggee. If you need a specific process (e.g., a 32-bit process in your case) you need to use the '.sym reload' since the details of the symbols are not available at the debugger (host).
-
so, if i just copy symbol dir from debugee to debugger it shall be ok ?
-
No still it needs to '.sym reload' to build a symbol table. You can add symbols manually if you want.
-
oh.. good!
-
But still I think the best way is to '.sym reload' one time (e.g., start the process and then .sym reload pid xxx), then use the symbol table for the rest of your debugging commands.
-
yeah, im doing so already :)
-
-
I recently back to write windows kernel. Is github copilot useful for developing kernel ?
-
(Strong IMHO) I'd rather have full understanding and control over my code. Especially given the fact that windows kernel programming environment has a lot of extra limitations of what you can do.
-
Agree. I'm using it for almost one month, although it's helpful in some cases but doesn't make good suggestions most of the times.
-
whatever, it is free for me
-
It's not about the money :)
-
is it feasible to use hyperdbg for reversing user mode applications that have heavy anti-debug protections currently?
I've tried starting and attaching to notepad with local VMI but my system crashes in 10 - 30 seconds, I get it's listed as unstable & under development but wondering if I'm missing anything or other ways to reverse user mode apps -
HyperDbg is currently stable, with most of its functionalities now available in Debugger Mode rather than VMI Mode.
I recommend starting with OST2 videos, as HyperDbg is little bit different than classic Windows debuggers and requires users to be familiar with some specific concepts and considerations before using it.
https://www.youtube.com/playlist?list=PLUFkSN0XLZ-kF1f143wlw8ujlH2A45nZY -
Thanks! Will start watching
-
im trying to reverse heavy protected app, that loads itself to kernel layer and installs rootkit protection, nevertheless, im very close to break inside app code now. though i use vmware not vmi mode
-
so that's quite a tool :)
- 15 June 2024 (31 messages)
-
Joined.
-
-
Hi there! Kind of yes, but not just that. I'd say it's a software that manages some sort of virtualization overall. If we're talking about Intel specifically, it's a software for managing VMX mode execution of CPU (put aside platform and external devices for now). EPT is a feature of VMX. There are many other features as well.
-
-
If you're familiar with a concept of page faults, then it's the same thing, it's just not an exception but rather a "VMX event"
-
I mean yes, you could say so
-
-
Yes
-
-
You have to fill out the VMCS properly and completely and set handlers for vmx exits first.
-
Unfortunately, partial implementation of the hypervisor is not feasible
-
-
-
So you have a concept of host mode and a guest mode
-
Host mode is where hypervisor is executed, guest is where a guest OS is executing
-
whenever you execute vmlaunch instruction, you enter vmx guest mode
-
for that you need to initialize vmcs guest fields
-
then, in order to return to host mode, some sort of vmexit event is needed in guest mode
-
and surely you need properly configured vmx host vmcs fields
-
hopefully this clarifies how vmx works
-
As an additional resource, you might also find the "Hypervisor from Scratch" tutorial helpful in understanding how VMX works. You can access it here:
https://rayanfam.com/tutorials/TutorialsWe write about Windows Internals, Hypervisors, Linux, and Networks.
-
-
-
It depends on the type of the VMX event, like sometimes you need to readjust RIP value or something, but in general you don't need to reconfigure much between vmresumes
-
-
-
EPT describes guest physical memory to host physical memory mapping
-
What mode do you want to run your code in?
-
-
Good morning everyone. Have a nice day.
-
 Good Moring Ting Zhang Qi
Good Moring Ting Zhang Qi - 16 June 2024 (43 messages)
-
Good day!I have a shellcode in memory and I want to transfer control only to it.... just like vmware, qemu, their hypervisor, the kernel transfers control to a separate piece of memory, rather than virtualizing the host system
-
-
-
Hi! Still not sure what you mean by "virtualize"
-
You have a CPU, right. When VMX is enabled, you can execute either in VMX root or VMX non-root (guest) mode.
-
If you have a shell code, you may just execute it as either VMX root or VMX guest
-
Do you imply physical memory virtualization?
-
hi guys, am i stupid or thats not possible - when i use !epthook, can i print stack trace? i know that pause() will lose context, but is it possible to print trace when hook is triggered?
-
you need to provide a link to it in vmxcs, right?
-
Yes, I've mentioned it here
-
-
By virtualizing the current system, do you mean entering to VMX guest mode with a custom EPT?
-
Sorry to choke you on that one, but it's much easier to understand each other when you use common technical terms, which come from Intels Software Developers Manual in this case
-
if I virtualized the current system, how do I exit this mode? (host->guest->host?)
-
There are many vmexit conditions available in VMX. Like cpuid instruction for instance. I'd recommend skimming through vol 3 chapter 28 of Intel's SDM.
-
You cannot use the 'k' command within a !epthook script since it's a command not a script function, but you can write the functionality of the printing callstack by using a simple script.
-
I think I wrote something similar for one of my projects years ago, lemme check.
-
basically i need to go trough rsp, right ?
-
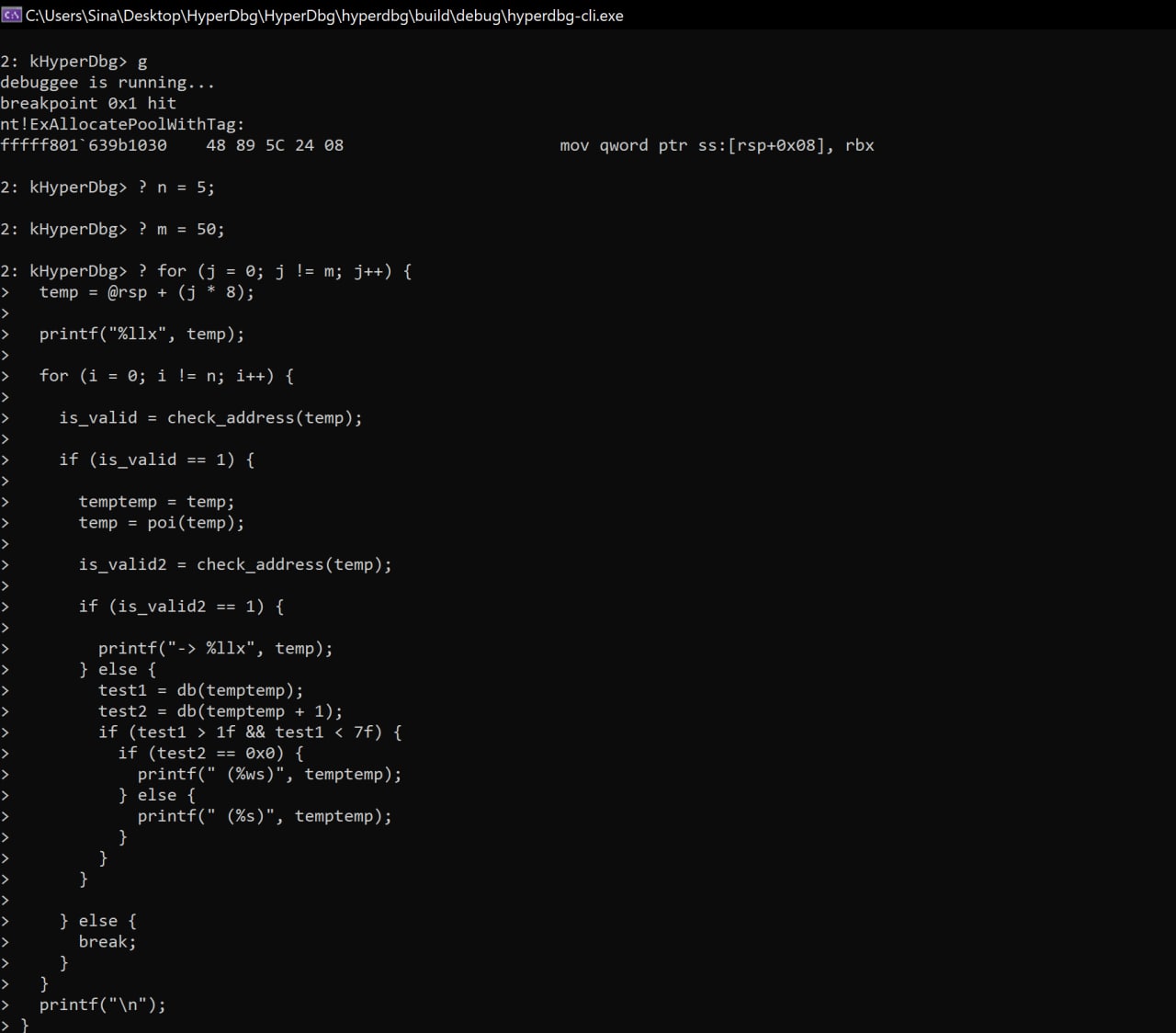
? n = 5;
? m = 50;
? for (j = 0; j != m; j++) {
temp = @rsp + (j * 8);
printf("%llx", temp);
for (i = 0; i != n; i++) {
is_valid = check_address(temp);
if (is_valid == 1) {
temptemp = temp;
temp = poi(temp);
is_valid2 = check_address(temp);
if (is_valid2 == 1) {
printf("-> %llx", temp);
} else {
test1 = db(temptemp);
test2 = db(temptemp + 1);
if (test1 > 1f && test1 < 7f) {
if (test2 == 0x0) {
printf(" (%ws)", temptemp);
} else {
printf(" (%s)", temptemp);
}
}
}
} else {
break;
}
}
printf("\n");
} -
-
-
Yes, you basically need something like the above script.
-
 hey there, is it possible to discard handling of cpuid instruction in the hypervisor and leave it to the cpu?
hey there, is it possible to discard handling of cpuid instruction in the hypervisor and leave it to the cpu? -
-
Unfortunately not, it is an unconditional vm exit
-
As @honorary_bot mentioned it's an unconditional VM-exit but generally HyperDbg won't touch the results of CPU's CPUID registers. So, the problem here is just VM-exit timing, other than that HyperDbg won't modify the CPUID results (we just set the hypervisor bit, and Hypervisor signature which can be ignored by a simple script).
-
then is there any way to prevent the guest from spamming cpuid instruction, it absolutely kills performance
-
I have a specific program which does that
-
if ran without hypervisor, performance is okay
-
Why don't you nop those CPUID instruction?
-
I believe it uses cpuid to get information from it plus time measurements
-
You can write a HyperDbg script to nop all occurrence of CPUIDs. Something like this:
!cpuid pid XX {
// CPUID = 0F A2
eb(@rip, 90);
eb(@rip + 1, 90);
} -
You can also find the execution of RDTSC/RDTSCP instructions for timing by using the !tsc command and nop it similar to the above script. Also, manual investigation might be needed to avoid breaking the process's semantics.
https://docs.hyperdbg.org/commands/extension-commands/tsc!tsc (hook RDTSC/RDTSCP instruction execution) | HyperDbg DocumentationDescription of the '!tsc' command in HyperDbg.
-
Man, btw, there is a tiny case where you should still adjust cpuid result for the guest. You need to readjust cr4.osxsave and cr4.pke to reflect not the host mode, but the guest mode when returning data to the guest. Those cpuid bits depend on cr4: leaf 1 and leaf 7 respectively
-
I think its not possible if the function which executes cpuid is virtualized
-
like what kind of virtualization? you mean obfuscated?
-
yes, these proprietary software protectors bruh
-
Maybe we should introduce techincal terms in this chat in order us to understand each other better? :)
-
😅
-
If I debug 32 bit, app shall i reduce instruction length to 4?
-
yes
-
not instruction length actually, memory size is the correct term
-
Yea, got it, j*8 => j*4 to print out 32 bit chunks
- 17 June 2024 (93 messages)
-
-
Yes, you need to disable exceptions/faults/traps (not exactly interrupts in HyperDbg terms). Anyway, both of them are possible in HyperDbg by using the !exception and !interrupt commands along with short-circuiting.
Please check:
https://docs.hyperdbg.org/commands/extension-commands/exception
https://docs.hyperdbg.org/tips-and-tricks/misc/event-short-circuiting!exception (hook first 32 entries of IDT) | HyperDbg DocumentationDescription of the '!exception' command in HyperDbg.
-
You need something like this:
!exception 1 pid XX {
event_sc(1);
} -
-
Other than, if you're dealing with the Debugger Mode, you can also tell HyperDbg not to intercept Traps or Breakpoints and later short-circuit it by the !exception command. Something like :
test breakpoint off
test trap off -
No difference, works the same in both user-mode and kernel-mode.
-
-
-
Use the '!dr' command along with short-circuiting mechanism:
https://docs.hyperdbg.org/commands/extension-commands/dr!dr (hook access to debug registers) | HyperDbg DocumentationDescription of the '!dr' command in HyperDbg.
-
-
@instw0 check these videos:
https://www.youtube.com/watch?v=OBcTwRkCE68&list=PLUFkSN0XLZ-kF1f143wlw8ujlH2A45nZY&index=50
https://www.youtube.com/watch?v=Z6HAO4btkCM&list=PLUFkSN0XLZ-kF1f143wlw8ujlH2A45nZY&index=60Dbg3301: HyperDbg 08 06 Debug Register MonitoringView the full free MOOC at https://ost2.fyi/Dbg3301. This course is an introductory guide to HyperDbg debugger, guiding you through the initial steps of using HyperDbg, covering essential concepts, principles, debugging functionalities, along with practical examples and numerous reverse engineering methods that are unique to HyperDbg. Whether you have an interest in reverse engineering or seek to elevate your reverse engineering skills with hypervisor-assisted approaches, this course provides a solid foundation for starting your journey.
-
exactly
-
Just make sure to use a printf to make sure it works as expected since I never test short-circuiting with the '!dr' events.
-
But it should work
-
-
add semicolon
-
-
event_sc
-
-
-
reconnect to HyperDbg? This error is not related to this event.
-
Another unrelated error happened there.
-
-
-
use it like :
!dr script {
event_sc(1);
printf("ignoring debug reg modification from %s, pid: %x\n", $pname, $pid);
} -
It's okay, you just need to tell HyperDbg not to intercept breakpoints/traps if you want to use Windbg.
-
this one
-
-
What do you mean?
-
-
-
You mean HyperDbg didn't intercept hardware breakpoint accesses? or it ignore them successfully as expected?
-
-
-
you mean once you try to access them (view the list of debug breakpoints) windbg won't show them?
-
-
I don't understand what you're trying to do. 🙂
If you want to ignore them using the '!dr' command, then why do you expect them to be triggered? -
HyperDbg can also manually inject #DBs which is how debug breakpoint registers notify about their trigger events.
https://docs.hyperdbg.org/commands/scripting-language/functions/events/event_injectevent_inject | HyperDbg DocumentationDescription of the 'event_inject' function in HyperDbg Scripts
-
the hypervisor does not seem to handle the single step exception correctly (rflags.tf ) . I wanted to try to do processing through windbg
-
Why? HyperDbg's 't' command has problem? 🤨
-
Is it also the same for the instrumentation step-in (the 'i' command)?
-
No, no.... this https://howtohypervise.blogspot.com/2019/01/a-common-missight-in-most-hypervisors.htmlA Common Missight in Most Hypervisors
Generally, when a hypervisor encounters a VM exit, it is because it needs to emulate the effects of an instruction, be it CPUID, RDMSR, or E...
-
-
-
Ah, got it.
-
-
When you run (test trap off) HyperDbg won't handle traps anymore. Everything is passed to the OS (Windbg).
-
No the problem is that cpuid will cause VM-exit before trap flag by default in Intel processors.
-
-
CPUID unconditionally cause a VM-exit and in HyperDbg a trap flag (#DB) will also cause a VM-exit but in Intel processors, CPUID has precedence over #DB (or more accurately RFLAGs.TF), that's why HyperDbg first receives and handles CPUIDs then processor triggers trap flag.
-
I'm thinking of a fast patch to this. Are you currently stepping through these instructions? I mean how do you test it?
-
-
-
-
I think this can be handled by a combination of the '!exception' command and the '!cpuid' command, but not sure. 🧐
-
-
-
Wait a moment, I'll make a patch, and will let you know.
-
@instw0 pls checkout to this branch and recompile HyperDbg:
https://github.com/HyperDbg/HyperDbg/tree/trap-cpuidGitHub - HyperDbg/HyperDbg at trap-cpuidState-of-the-art native debugging tool. Contribute to HyperDbg/HyperDbg development by creating an account on GitHub.
-
Let me know if it fixes the issue, I added this check to this branch (but not test it):
https://github.com/HyperDbg/HyperDbg/commit/ddbf929aa2043d0a65887e4fd428bfe6afddd43fdetect and handle CPUIDs with TRAP flag · HyperDbg/HyperDbg@ddbf929State-of-the-art native debugging tool. Contribute to HyperDbg/HyperDbg development by creating an account on GitHub.
-
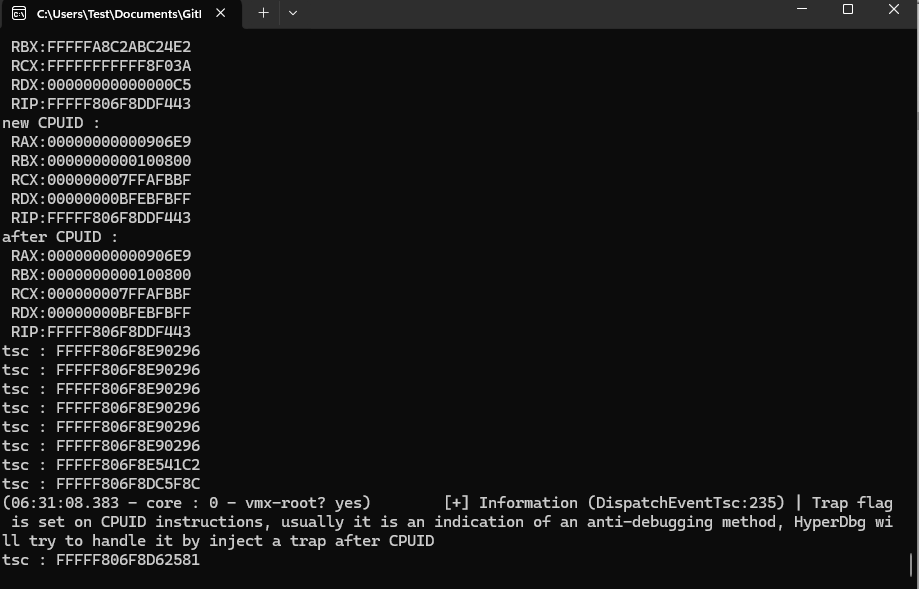
no, it didn't fix the problem (
after CPUID :
RAX:00000000000906E9
RBX:0000000000100800
RCX:000000007FFAFBBF
RDX:00000000BFEBFBFF
RIP:FFFFF8085560F443
tsc : FFFFF808556C0296
tsc : FFFFF808556C0296
tsc : FFFFF808556C0296
tsc : FFFFF808556C0296
tsc : FFFFF808556C0296
tsc : FFFFF808556C0296
tsc : FFFFF808556841C2
tsc : FFFFF808555F5F8C
tsc : FFFFF80855592581
fffff808`55592584 68 12 6C 45 A9 push 0xFFFFFFFFA9456C12
0: kHyperDbg> -
Don't use the '!tsc' for now, just try to see if HyperDbg shows this message or not?
Does it show this message? -
no (((
debuggee is running...
NtQuerySystemInformation : FFFFF805B9C2457F RCX: 000000000000000B
NtQuerySystemInformation : FFFFF805B9E11A29 RCX: 000000000000000B
NtQuerySystemInformation : FFFFF805B9E8952D RCX: 0000000000000023
New NtQuerySystemInformation : FFFFF805B9E8952D RCX: 0000000000000000
NtQuerySystemInformation : FFFFF805B9E61046 RCX: 000000000000000B
NtQuerySystemInformation : FFFFF805B9F33FF4 RCX: 000000000000000B
NtQuerySystemInformation : FFFFF805B9C2457F RCX: 000000000000000B
NtQuerySystemInformation : FFFFF805B9E11A29 RCX: 000000000000000B
NtQuerySystemInformation : FFFFF805B9C2457F RCX: 000000000000000B
NtQuerySystemInformation : FFFFF805B9E11A29 RCX: 000000000000000B
NtQuerySystemInformation : FFFFF805B9C2457F RCX: 000000000000000B
NtQuerySystemInformation : FFFFF805B9E11A29 RCX: 000000000000000B
after CPUID :
RAX:0000000000000001
RBX:FFFFF38D666824E2
RCX:FFFFFFFFFFF8F03A
RDX:00000000000000C5
RIP:FFFFF805B9E8F443
new CPUID :
RAX:00000000000906E9
RBX:0000000000100800
RCX:000000007FFAFBBF
RDX:00000000BFEBFBFF
RIP:FFFFF805B9E8F443
after CPUID :
RAX:00000000000906E9
RBX:0000000000100800
RCX:000000007FFAFBBF
RDX:00000000BFEBFBFF
RIP:FFFFF805B9E8F443
fffff805`b9e12583 90 nop -
So, the way that VMProtect detects hyperviosr (HyperDbg) is not based on this trick.
-
-
-
-
@HughEverett hi, not really understand scala language. Is scala code developed in visual studio community ? and Do i need FPGA to run hwdbg ?
-
-
It depends, CPUID is an unconditional VM-exit but RDTSC/RDTSCP only cause VM-exit when you use the !tsc command in HyperDbg.
-
Hi,
Scala is used as a part of porting HyperDbg into the hardware (Chip & FPGA) debugging (hwdbg). It is mainly written based on the Chisel language: https://www.chisel-lang.org
If you want to test and use hardware debugging, then you need an FPGA. Basically, this Scala code that I wrote for hwdbg generates Verilog and SystemVerilog (HDL) codes that are synthesizable into FPGAs.
For the issue I posted on GitHub early today, I didn't mean to modify the Scala code, I just meant to show you how I implemented the evaluation engine in hardware, so basically a simple modification on the INC++ and DEC++ operands in the C code is needed.
I wrote the evaluation engine in Scala (https://github.com/HyperDbg/HyperDbg/blob/45b88f652d071e0f3c11b1f84b8a2a2d6556972a/hwdbg/src/main/scala/hwdbg/script/eval.scala#L97).
The concept is the same, HyperDbg makes a script buffer using C/C++ codes and once the script buffer is ready, we'll send it to the hwdbg (through either Serial port or shared BlockRAM). The generated hardware part (the Scala code) is responsible for running those script buffers that we generated in the script engine.Chisel | ChiselSoftware-defined hardware
-
@HughEverett By the way, is it even possible to dump debugee whole process memory, like creating big buffer in Ram, and dump that into file, as process continues? Transferring over serial connection is no option for sure :)
-
HyperDbg has a dump command (previously requested by @ricnar) and documented:
https://docs.hyperdbg.org/commands/extension-commands/dump!dump (save the physical memory into a file) | HyperDbg DocumentationDescription of '!dump' command in HyperDbg.
-
But it transfer buffer over serial.
-
yes, i know that
-
thats issue
-
2mb transfer is around minute or so
-
If you need any other kind of implementation, I think you can easily implement it by creating a new command based on this dump command.
-
and of course, create a PR so everyone can use it. 🙂
-
ok, will see :) thanks
-
I'm sorry, the main branch was copied without corrections.
-
-
-
-

-
-
-
Could you share disassembly of instructions after popfq?
-
No, none of them are related to EPT hooks.
-
rflag?
-
Let me send you a link about its design.
-
Please check this doc:
https://research.hyperdbg.org/assets/documents/kernel-debugger-design-1st-edition.pdf -
It explains how these commands (specially the instrumentation step-in) is implemented.
- 18 June 2024 (8 messages)
-
through the eflags register like other debuggers + mtf?
-
-
-
Only the 'i' command (instrumentation step-in) uses MTF (Monitor Trap Flag). Other stepping command like 't' is implemented same as WinDbg by using RFLAGS's TF.
-
NMI is not realted to step-in or step-over, HyperDbg just uses NMI to halt (pause) all cores in the Debugger Mode.
-
Not sure if I correctly understand what you mean. 🤔
What is event(!cpu)? -
when we use events !cpuid, !rdtsc do we configure the vmxcs structure to vm-exit when an event occurs?
-
- 19 June 2024 (25 messages)
-
For !tsc Yes, for !cpuid No. CPUID is unconditional VM-exit. Here is a list of instructions with unconditional VM-exit.
-
We process it as VM-exit, not interrupt.
-
-
-
RDTSC is configured from VMCS, VMCALL is unconditional VM-exit and !msrread !msrwrite use MSR Bitmaps. Take a look at Hypervisor From Scratch, I think it gives you an idea how HyperDbg works internally:
https://rayanfam.com/tutorials/TutorialsWe write about Windows Internals, Hypervisors, Linux, and Networks.
-
-
-
You need to provide more details. What is the generation of your processor? which version of Windows? and how to reproduce it?
-
yes, I've read it, I just wanted to clarify that the debugger is at the event !cpuid, !rdtsc set conditions in the vmxsc structure? then vmm receives a notification(or vmexit)?
-
-
Not related to hyperdbg, but vmprotect does not care if you break at cpuid or at the nop. https://github.com/jmpoep/vmprotect-3.5.1/blob/d8fcb7c0ffd4fb45a8cfbd770c8b117d7dbe52b5/runtime/core.cc#L771
-
RDTSC?
-
Ah yes, my bad. It actually cares 😀 https://github.com/jmpoep/vmprotect-3.5.1/blob/d8fcb7c0ffd4fb45a8cfbd770c8b117d7dbe52b5/runtime/core.cc#L306
-
Conditions checks for each extension command is basically software-side implemented. RDTSC/RDTSCP cause conditional VM-exits (not remember, either on primary or secondary proc-based VMCS controls).
-
Development progress update: hwdbg has reached the point where it can run HyperDbg scripts (dslang) for chip/FPGA debugging. Still under development!
https://github.com/HyperDbg/HyperDbg/tree/dev/hwdbg -
-
@xmaple555 we need to think of the best way to parse scripts of the hwdbg debugger. The registers and pseudo-registers of the hwdbg is different from x64 registers. 🤔
-
Basically, hwdbg registers are like @hw_pin0, @hw_pin1, @hw_pin2, ..., @hw_pinX and @hw_port0, @hw_port1, @hw_port2, ..., @hw_portX. We need to find the best way of adding these registers (and new pseudo-registers) to the parser.
-
accordingly !vmcall, !dr... they also cause the exit from the virtual machine (vmexit)
-
VMCALL is unconditional, !dr needs configuration. Pls check this file as it's the file responsible for configuring events:
https://github.com/HyperDbg/HyperDbg/blob/master/hyperdbg/hprdbgkd/code/debugger/events/ApplyEvents.cHyperDbg/hyperdbg/hprdbgkd/code/debugger/events/ApplyEvents.c at master · HyperDbg/HyperDbgState-of-the-art native debugging tool. Contribute to HyperDbg/HyperDbg development by creating an account on GitHub.
-
hey there, im trying to build solution and getting:
-
have latest VS SDK and WDK
-
i commented out definitions in ntioapi.h, but i dont know if it is valid solution
-
it conflicted with winnt.h
-
another question, im trying to use firstchance exception handling, im executing !epthook <hidden> code {31 c0 f7 f0} <- division by zero. but debugger console stays in infinite loop
- 20 June 2024 (66 messages)
-
有没有自己人?😁
-
没有
-
thank you, did I understand correctly(in general):
configuring vmxcs to be notified when an event occurs -> processing in vmm? -
i add a check rflags.tf in !tsc, and:
-
-
-
Ah, this one is also mentioned by another person in issues. This one should be updated in the phnt repo that we used it as a submodule. We could also update HyperDbg's fork and comment it. I'll fix it.
-
Not sure what you trying to do? The division by zero error you're trying produce is handled in VMX root-mode because all of the events (except !epthook2, not !epthook) execute assembly in VMX root-mode, so it's not handled by guest (Windows) IDT and it's passed to HyperDbg's HOST IDT exception handler.
-
Yes
-
Just added a check? Any modification to the TF Flag?
-
-
-
-
I'm trying to do remote debugging with 2 physical machines over COM but the connection never seems to complete, the debugger stays on
HyperDbg> .debug remote serial 115200 com1
Waiting for debuggee to connect...
And the debugee:
HyperDbg> .debug prepare serial 115200 com3
current processor vendor is : GenuineIntel
virtualization technology is vt-x
vmx operation is supported by your processor
I've tested the COM connection with PuTTY and all appears to be working fine there, any suggestions on what I can do to debug/fix the issue? -
im trying to stop app in particular state by modifying code to raise division exception, now app stops with unhandled exception and windows popup appears. i can take dump, state is intact, however, in traces i can see windows exception handler mechanism, so real trace is not accessible. actually i wanted to cause BSOD, but it seems its not so easy for usermode
-
Yes a trap flag generates a #Db.
-
and is it being processed?
-
If I were in your shoes, I tried to make a simple application with your target technique (popfq TF), and I try to trigger the behavior in HyperDbg like showing a message using (LogInfo) without modifying anything. Once I was sure that this technique can be correctly detected (by seeing the message), then I try to modify the guest state. I think this is the best approach to handle this VMProtect technique.
-
I'm trying
-
Yes, but it depends on when CPU gives us this #Db, the reason such a technique exists is because CPUID has precedence over #Db's exception bitmap vm-exit.
-
-
Ah, unfortunately this feature is not working as expected. We previously had a discussion in this group and conclude that this feature is not working. You need to use a virtual serial device.
-
-
-
.
-
Larry you can follow this discussion, it's probably the problem with verifying packets.
-
Still don't understand what you're trying to do but if you want to trigger an exception in your target user-mode app, you need to inject an event in HyperDbg by using these functions:
https://docs.hyperdbg.org/commands/scripting-language/functions/events/event_inject
And:
https://docs.hyperdbg.org/commands/scripting-language/functions/events/event_inject_error_code
These are the functions that deliver exception to the guest debuggee application. The assembly code you used in your event will cause division by zero in HyperDbg's VMM which is simply handled in VMX root-mode and it's ignored by HyperDbg's division by zero exception handler.event_inject | HyperDbg DocumentationDescription of the 'event_inject' function in HyperDbg Scripts
-
Depends on how CPU behaves in this case. If it triggers immediately then you need to inject a #DB.
-
User-mode try/catch?
-
-
Are you analyzing a driver?
-
-
-
I think you need to create a user-mode application with the same technique.
-
It's easier to modify a user-mode application and introspect it's behavior. Try to make a similar check function check in user-mode.
-
And also post your function here if it's possible. I'm gonna check it too.
-
-
No, it's the case for HyperDbg. Windows (OS) doesn't have any details about the presence of a top-level (ring -1) debugger.
-
In VMI mode, traps/breakpoints are not intercepted by default.
-
In the Debugger Mode, traps/bps are intercepted.
-
!monitor w 001995A4 l 4 pid 01cc script {
if (db(001995A4) == c3){
pause();
}
}
why this script is slow as hell? it freezes debugee process. if i remove if condition its more less ok -
Is it (the entire 4kb of the target page) located on a page with high rate of memory access?
-
i think so.. there is buffer prepared for network sending
-
So, that's the reason. HyperDbg puts hook on entire 4 kb granularity of the page boundary. Not just 4 bytes. Because it's how EPT works.
-
mmm
!monitor w 001995A4 l 4 script {
printf("BUF ACCESSED BY %s stack:%x\n",$pname,@esp);
printf("BUF CONTENT \n");
for (i = 0; i < 10; i++){
printf("%x ",db(001995A4+i));
}
printf("\n");
}
this script works perfect -
So, each access to this 4kb cause a VM-exit, but HyperDbg filters it and only show you the accesses on your target address range.
-
Why? 🤔
-
i also wonder :D
-
Can you check the entire page boundary?
-
all 4kb ?
-
Yes. Get a printf from it
-
And also not sure if you already knew it or not but the $context pseudo-register shows you the address of the memory accessed by the instruction that triggered the hook.
https://docs.hyperdbg.org/commands/extension-commands/monitor#context!monitor (monitor read/write/execute to a range of memory) | HyperDbg DocumentationDescription of the '!monitor' command in HyperDbg.
-
what i need to do to achieve it ?
-
i need to montor 001995A4+4kb ?
-
No, the page boundary start from PAGE_ALIGN(001995A4) which means you need sth like:
00199000 l fff -
Or from 199000 to 199fff
-
aha...
!monitor w 199000 l fff pid 1a00 script {
printf("Buffer accessed\n");
}
i get a ton of accesses, but at least it shows something -
Ah, so that's the reason
-
The rate of access is too high
-
will try to add if condition now
-
or will it fail ?
-
It does not make that much difference.
-
Once you try to hook 001995a4, HyperDbg will automatically hook the entire page boundary (00199000 to 00199fff) for you.
-
i see..
-
It just doesn't show you once it's not within the range but not showing you doesn't mean it didn't happen.
-
yes, understood
- 21 June 2024 (35 messages)
-
群里天天都在聊啥
-
看不懂英语
-
有没有自己人讲讲😊
-
祁 同伟
This is an English-speaking group. Please send your messages in English only. You may use an online translator if needed.
___
这是一个英语群组。请仅以英语发送您的消息。如有需要,您可以使用在线翻译。 -
@HughEverett Can I commit and push to submodule for phnt ?
-
I believe we should wait for the 'phnt' authors to fix the issue. Modifying the submodules ourselves can lead to problems when updating them in the future. Even though we had forced to do it once before, it's usually not a good idea. Let's give the phnt authors some time to address the issue, then we can update accordingly.
I've created an issue for them here: https://github.com/winsiderss/phnt/issues/34
If they are slow in fixing the issue, we will inevitably have to update our forked submodule.Build issue with newest SDK/WDK (redefinition of structures) · Issue #34 · winsiderss/phntHi, I would like to report an issue regarding the compilation of HyperDbg against the newest SDK/WDK. It seems that the new SDK has the definition of _FILE_STAT_LX_INFORMATION and other functions m...
-
I think in the meanwhile you can switch to this version of phnt https://github.com/oberrich/phnt_nightly as the fix for this issue was already merged there
This one is basically the same phnt but it automatically obtains it from the systeminformer repository so as soon as they push any updates to the systeminformer's phnt(they're first merging new stuff to the systeminformer and then after some time merging to the phnt repo) they'll end up in that repo too.GitHub - oberrich/phnt_nightly: Native API header files for the Process Hacker project (nightly).Native API header files for the Process Hacker project (nightly). - oberrich/phnt_nightly
-
hi, stupid question - in script can i write out current timestamp ?
-
As long as I remember, I didn't implement a timing function. 🤔
Though not sure 😄
Because I remember at some point we had a discussion about the time with someone else but I don't know whether we ended up implementing anything or not.
Anyway, go and modify this function, add a LogInfo("message") above this function and LogInfo is a function we use for debugging HyperDbg itself. It shows the current time. -
And if you're interested in adding this as a separate function to HyperDbg, create an issue in the GitHub and I'll add it (hopefully) to the next version.
-
I tried hyperdbg(master) and hyperdbg(cpuid_flags). neither can handle cpuid and rdtsc with flags.tf . including with the test trap off option.
-
-
Can you send just the code files? Like the main trick assembly codes.
-
BOOL bExceptionHit = FALSE;
__try {
_asm
{
pushfd
or dword ptr[esp], 0x100
popfd
cpuid
// Set the Trap Flag
// Load value into EFLAGS register
nop
}
}
__except (EXCEPTION_EXECUTE_HANDLER) {
bExceptionHit = TRUE;
// An exception has been raised –
// there is no debugger.
}
if (bExceptionHit == FALSE)
printf("A debugger is present.n");
else
printf("There is no debugger present.n"); -
@hyperdbg / Public archive of HyperDbg Telegram messages.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- 01 Jun 2024 (1)
- 03 Jun 2024 (3)
- 04 Jun 2024 (75)
- 05 Jun 2024 (2)
- 06 Jun 2024 (3)
- 08 Jun 2024 (3)
- 09 Jun 2024 (5)
- 10 Jun 2024 (2)
- 12 Jun 2024 (1)
- 13 Jun 2024 (98)
- 14 Jun 2024 (26)
- 15 Jun 2024 (31)
- 16 Jun 2024 (43)
- 17 Jun 2024 (93)
- 18 Jun 2024 (8)
- 19 Jun 2024 (25)
- 20 Jun 2024 (66)
- 21 Jun 2024 (35)
- 22 Jun 2024 (3)
- 23 Jun 2024 (4)
- 24 Jun 2024 (3)
- 26 Jun 2024 (4)
- 27 Jun 2024 (2)
- 28 Jun 2024 (4)
- 29 Jun 2024 (10)
- 30 Jun 2024 (20)